A genetic algorithm in data mining is an advanced method of data classification. Data classification incorporates two steps, i.e. learning step and the classification step. The classification model is constructed in the learning step, and in the classification step, the model predicts the output for the provided input.
A genetic algorithm is based on the basic principle of natural evolution where the fittest individual survives at the end. We use the algorithm for solving optimization problems.
Content: Genetic Algorithm in Data Mining
- What is a Genetic Algorithm?
- Working of Genetic Algorithm with Example
- Genetic Algorithm in Data Mining
- Advantages and Disadvantages
- Application of Genetic Algorithm
Genetic algorithms (GA) are adaptive search algorithms- adaptive in terms of the number of parameters you provide or the types of parameters you provide. The algorithms classify the best optimal solution among the several solutions, and its design is based on the natural genetic solution.
Genetic algorithm emulates the principles of natural evolution, i.e. survival of the fittest. Natural evolution propagates the genetic material in the fittest individuals from one generation to the next.
The genetic algorithm applies the same technique in data mining – it iteratively performs the selection, crossover, mutation, and encoding process to evolve the successive generation of models.
The components of genetic algorithms consist of:
- Population incorporating individuals.
- Encoding or decoding mechanism of individuals.
- The objective function and an associated fitness evaluation criterion.
- Selection procedure.
- Genetic operators like recombination or crossover, mutation.
- Probabilities to perform genetic operations.
- Replacement technique.
- Termination combination.
At every iteration, the algorithm delivers a model that inherits its traits from the previous model and competes with the other models until the most predictive model survive.
If we count the phases of the genetic algorithm, then we would distribute the entire algorithm into six phases, as you can see in the image below:
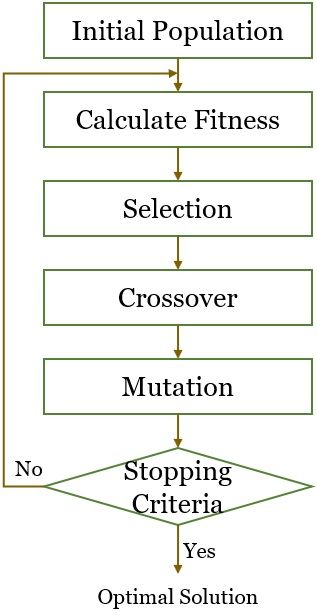
Let us learn about each phase in detail:
Initial population
Being the first phase of the algorithm, it includes a set of individuals where each individual is a solution to the concerned problem. We characterize each individual by the set of parameters that we refer to as genes.
Calculate Fitness
A fitness function is implemented to compute the fitness of each individual in the population. The function provides a fitness score to each individual in the population. The fitness score is the probability of the individual selection in the reproduction process.
Selection
The selection process selects the individuals with the highest fitness score and is allowed to pass on their genes to the next generation.
Crossover
It is a core phase of the genetic algorithm. Now the algorithm chooses a crossover point within the parents’ genes chosen for mating.
The algorithm keeps generating the offspring until the groups of parents exchange their genes until they reach the crossover point. Now, these newly created offspring are added to the population.
Mutation
The mutation phase inserts random genes into the generated offspring to maintain the population’s diversity. It is done by flipping random genes in new offspring.
Termination
The iteration of the algorithm stops when it produces offspring that is not different from the previous generation. It is said to have produced a set of solutions for the problem at this stage.
Working of Genetic algorithm with Example
To overview the evolution of models until the best optimal solution occurs, we will discuss a simple example.
Suppose a company wants to increase its profit, so it came up with the idea of sending promotional mail along with the coupons. This promotional mail must increase the sales and profit of the company; however, it can also produce a negative result of revenue loss.
So here, the genetic algorithm has to come up with the solution that what optimum number of coupons must be added to each promotional mail to maximize the company’s profit.
The initial view would be to add as many coupons as possible to maximize the profit. This will let the customer use all the coupons and maximize the company’s profit.
Well, some factors may complicate the idea of adding coupons to the mail to maximize the profit, such as:
- Adding more coupons in the mail would increase the postal cost, ultimately reducing the profit.
- Sending fewer coupons will also reduce the opportunity to gain profit and lead to a potential loss in revenue.
- Adding too many coupons may reduce the customer’s interest in using any coupon at all.
In such a case, we need an optimum number of coupons that must be sent in each mail to maximize the profit.
The image below represents the evolution obtained by implementing the genetic algorithm for this problem. Over the three generations, we have obtained the optimum number of coupons that must be sent in each mail.
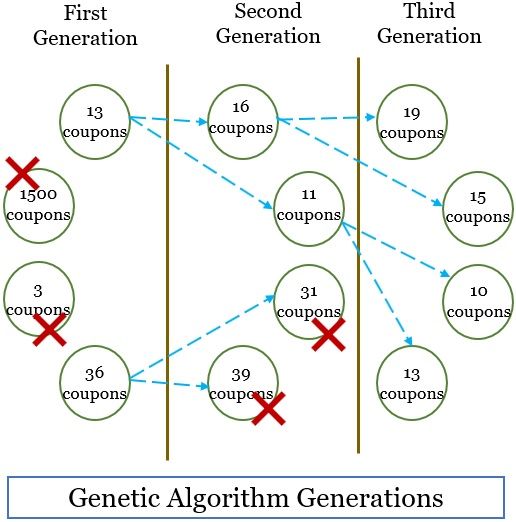
You can notice that in every generation, the fittest option survives. The generation keeps on evolving until the generation represents the optimal number of coupons per mail.
Although it is a very basic example, we have not discussed how these numbers are generated at each iteration. Nor we have discussed how we have eliminated the abnormal numbers. We have complex calculations to perform these kinds of functions. Hopefully, the example gives you a basic idea of how the genetic algorithm works.
Genetic Algorithms in Data Mining
So far, we have studied that the genetic algorithm is a classification method that is adaptive, robust and used globally in situations where the area of classification is large. The algorithms optimize a fitness function based on the criteria preferred by data mining so as to obtain an optimal solution, for example:
- Knowledge discovery system
- MASSON system
However, the data mining application based on the genetic algorithm is not as rich as the application based on fuzzy sets. In the section ahead, we have categorized some systems based on the genetic algorithm used in data mining.
Regression
Data mining identifies human interpretable patterns; it includes a prediction that determines a future value from the available variable or attributes in the database. The basic assumption of the linear multi regression model is that there is no interaction among the attributes.
GA handles the interaction among the attributes in a far better way. The non-linear multi regression model uses GA to get single out from the training data set.
Association Rules
Multiple objective GA deals with the problems with multiple objective functions and constraints, to determine the optimal set of solutions. None of the solutions from this set must exist in the search space that can dominate any member of this set.
Such algorithms are used for rule mining with a large search space with many attributes and records. To obtain the optimal solutions, multi-objective GA performs the global search with multiple objectives. Such as a combination of factors like predictive accuracy, comprehensibility and interestingness.
Advantages and Disadvantages
Advantages
- Easy to understand as it is based on the concept of natural evolution.
- Classifies an optimal solution from a set of solutions.
- GA uses the pay off information instead of the derivative to yield an optimal solution.
- GA backs multi-objective optimization.
- GA is an adaptive search algorithm.
- GA also operates in a noisy environment.
Disadvantages
- An improper implementation may lead to a solution that is not optimal.
- Implementing fitness function iteratively may lead to computational challenges.
- GA is time-consuming as it deals with a lot of computation.
Applications of GA
GA is used in implementing many applications let s discuss a few of them.
- Economics: In the field of economics GA is used to implement certain models that conduct competitive analysis, decision making, and effective scheduling.
- Aircraft Design: GA is used to provide the parameters that must be modified and upgraded in order to get a better design.
- DNA Analysis: GA is used to establish DNA structure using spectrometric information.
- Transport: GA is used to develop a transport plan that is time and cost-efficient.
- Data mining: GA classify a large set of data to determine the optimal solution to the concerned problem.
And there are many more.
So, this content provides you with the basic idea of a genetic algorithm, and how it processes to determine the optimal solution from the set of the solutions. Basically, the algorithm has six stages i.e. initialization, fitness function, selection, crossover, mutation and termination.
The content also provides you with the benefits and limitations of the algorithm along with its application.
Leave a Reply