Pipelining organizes the execution of the multiple instructions simultaneously. Pipelining improves the throughput of the system. In pipelining the instruction is divided into the subtasks. Each subtask performs the dedicated task.
The instruction is divided into 5 subtasks: instruction fetch, instruction decode, operand fetch, instruction execution and operand store. The instruction fetch subtask will only perform the instruction fetching operation, instruction decode subtask will only be decoding the fetched instruction and so on the other subtasks will do.
In this section, we will discuss the types of pipelining, pipelining hazards, its advantage. So let us start.
Content: Pipelining in Computer Architecture
Introduction
Have you ever visited an industrial plant and see the assembly lines over there? How a product passes through the assembly line and while passing it is worked on, at different phases simultaneously. For example, take a car manufacturing plant. At the first stage, the automobile chassis is prepared, in the next stage workers add body to the chassis, further, the engine is installed, then painting work is done and so on.
The group of workers after working on the chassis of the first car don’t sit idle. They start working on the chassis of the next car. And the next group take the chassis of the car and add body to it. The same thing is repeated at every stage, after finishing the work on the current car body they take on next car body which is the output of the previous stage.
Here, though the first car is completed in several hours or days, due to the assembly line arrangement it becomes possible to have a new car at the end of an assembly line in every clock cycle.
Similarly, the concept of pipelining works. The output of the first pipeline becomes the input for the next pipeline. It is like a set of data processing unit connected in series to utilize processor up to its maximum.
An instruction in a process is divided into 5 subtasks likely,

- In the first subtask, the instruction is fetched.
- The fetched instruction is decoded in the second stage.
- In the third stage, the operands of the instruction are fetched.
- In the fourth, arithmetic and logical operation are performed on the operands to execute the instruction.
- In the fifth stage, the result is stored in memory.
Now, understanding the division of the instruction into subtasks. Let us understand, how the n number of instructions in a process, are pipelined.
Look at the figure below the 5 instructions are pipelined. The first instruction gets completed in 5 clock cycle. After the completion of first instruction, in every new clock cycle, a new instruction completes its execution.
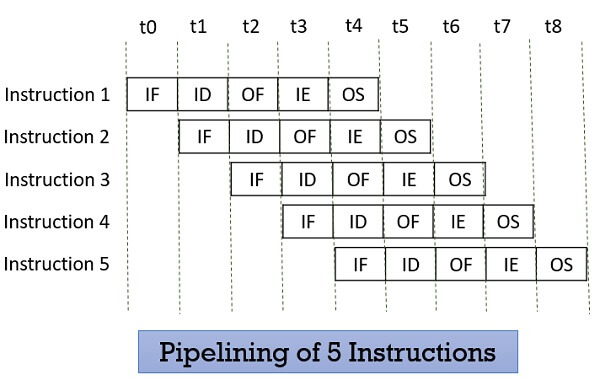
Observe that when the Instruction fetch operation of the first instruction is completed in the next clock cycle the instruction fetch of second instruction gets started. This way the hardware never sits idle it is always busy in performing some or other operation. But, no two instructions can execute their same stage at the same clock cycle.
Types of Pipelining
In 1977 Handler and Ramamoorthy classified pipeline processors depending on their functionality.
1. Arithmetic Pipelining
It is designed to perform high-speed floating-point addition, multiplication and division. Here, the multiple arithmetic logic units are built in the system to perform the parallel arithmetic computation in various data format. Examples of the arithmetic pipelined processor are Star-100, TI-ASC, Cray-1, Cyber-205.
2. Instruction Pipelining
Here, the number of instruction are pipelined and the execution of current instruction is overlapped by the execution of the subsequent instruction. It is also called instruction lookahead.
3. Processor Pipelining
Here, the processors are pipelined to process the same data stream. The data stream is processed by the first processor and the result is stored in the memory block. The result in the memory block is accessed by the second processor. The second processor reprocesses the result obtained by the first processor and the passes the refined result to the third processor and so on.
4. Unifunction Vs. Multifunction Pipelining
The pipeline performing the precise function every time is unifunctional pipeline. On the other hand, the pipeline performing multiple functions at a different time or multiple functions at the same time is multifunction pipeline.
5. Static vs Dynamic Pipelining
The static pipeline performs a fixed-function each time. The static pipeline is unifunctional. The static pipeline executes the same type of instructions continuously. Frequent change in the type of instruction may vary the performance of the pipelining.
Dynamic pipeline performs several functions simultaneously. It is a multifunction pipelining.
6. Scalar vs Vector Pipelining
Scalar pipelining processes the instructions with scalar operands. The vector pipeline processes the instruction with vector operands.
Pipelining Hazards
Whenever a pipeline has to stall due to some reason it is called pipeline hazards. Below we have discussed four pipelining hazards.
1. Data Dependency
Consider the following two instructions and their pipeline execution:
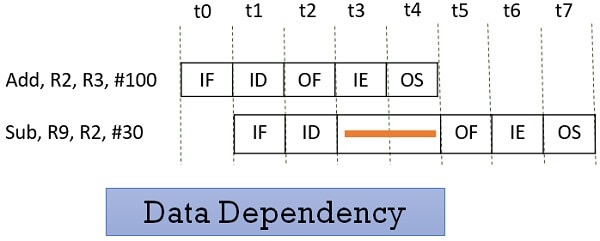
In the figure above, you can see that result of the Add instruction is stored in the register R2 and we know that the final result is stored at the end of the execution of the instruction which will happen at the clock cycle t4.
But the Sub instruction need the value of the register R2 at the cycle t3. So the Sub instruction has to stall two clock cycles. If it doesn’t stall it will generate an incorrect result. Thus depending of one instruction on other instruction for data is data dependency.
2. Memory Delay
When an instruction or data is required, it is first searched in the cache memory if not found then it is a cache miss. The data is further searched in the memory which may take ten or more cycles. So, for that number of cycle the pipeline has to stall and this is a memory delay hazard. The cache miss, also results in the delay of all the subsequent instructions.
3. Branch Delay
Suppose the four instructions are pipelined I1, I2, I3, I4 in a sequence. The instruction I1 is a branch instruction and its target instruction is Ik. Now, processing starts and instruction I1 is fetched, decoded and the target address is computed at the 4th stage in cycle t3.
But till then the instructions I2, I3, I4 are fetched in cycle 1, 2 & 3 before the target branch address is computed. As I1 is found to be a branch instruction, the instructions I2, I3, I4 has to be discarded because the instruction Ik has to be processed next to I1. So, this delay of three cycles 1, 2, 3 is a branch delay.
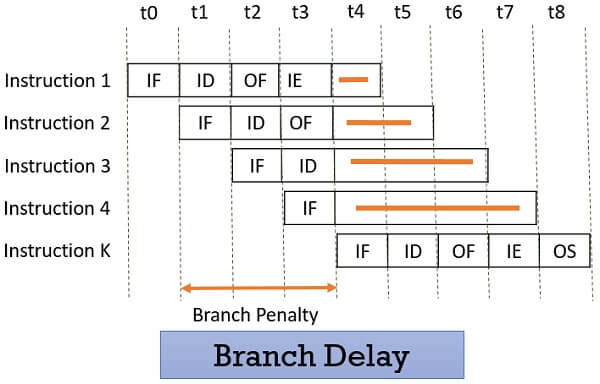
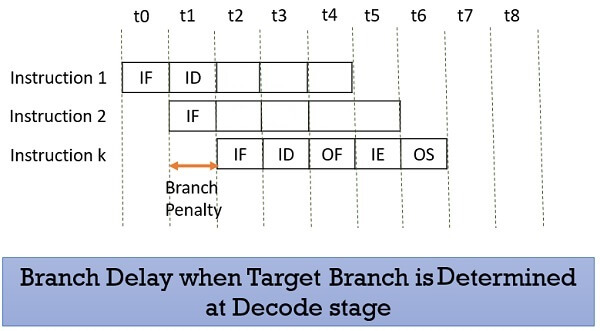
Prefetching the target branch address will reduce the branch delay. Like if the target branch is identified at the decode stage then the branch delay will reduce to 1 clock cycle.
4. Resource Limitation
If the two instructions request for accessing the same resource in the same clock cycle, then one of the instruction has to stall and let the other instruction to use the resource. This stalling is due to resource limitation. However, it can be prevented by adding more hardware.
Advantages
- Pipelining improves the throughput of the system.
- In every clock cycle, a new instruction finishes its execution.
- Allow multiple instructions to be executed concurrently.
Key Takeaways
- Pipelining divides the instruction in 5 stages instruction fetch, instruction decode, operand fetch, instruction execution and operand store.
- The pipeline allows the execution of multiple instructions concurrently with the limitation that no two instructions would be executed at the same stage in the same clock cycle.
- All the stages must process at equal speed else the slowest stage would become the bottleneck.
- Whenever a pipeline has to stall for any reason it is a pipeline hazard.
This is all about pipelining. So, basically the pipelining is used to improve the performance of the system by improving its efficiency.
Fateh Ali says
Very Informative Post.
I have a little problem in understanding the main topic Pipelining. Is pipelining a program, a process, stored in Processor or it is itself a processor. Please share some practical need of this pipelining? If we want to add some numbers or subtract them , how we can do it through pipelining?
Hope to here from You Soon!
Santosh Adhikari says
Very helpful content. Thanks for sharing it helps me to understand on pipeline concept
Alex says
Great content,thank you very much !
mahesh says
Thanks for the content
maganga says
well done, but I want to know in detail the way all pipeline stages are occured.
Ayesha says
Mazedar….
neha says
well done, but I want to know in detail about pipe hazards
safal mehar shrestha says
worthy🙌