Data reduction is a process that reduced the volume of original data and represents it in a much smaller volume. Data reduction techniques ensure the integrity of data while reducing the data.
The time required for data reduction should not overshadow the time saved by the data mining on the reduced data set. In this section, we will discuss data reduction in brief and we will discuss different methods of data reduction.
Content: Data Reduction in Data Mining
What is Data Reduction?
When you collect data from different data warehouses for analysis, it results in a huge amount of data. It is difficult for a data analyst to deal with this large volume of data.
It is even difficult to run the complex queries on the huge amount of data as it takes a long time and sometimes it even becomes impossible to track the desired data.
This is why reducing data becomes important. Data reduction technique reduces the volume of data yet maintains the integrity of the data.
Data reduction does not affect the result obtained from data mining that means the result obtained from data mining before data reduction and after data reduction is the same (or almost the same).
The only difference occurs in the efficiency of data mining. Data reduction increases the efficiency of data mining. In the following section, we will discuss the techniques of data reduction.
Data Reduction Techniques
Techniques of data deduction include dimensionality reduction, numerosity reduction and data compression.
1. Dimensionality Reduction
Dimensionality reduction eliminates the attributes from the data set under consideration thereby reducing the volume of original data. In the section below, we will discuss three methods of dimensionality reduction.
a. Wavelet Transform
In the wavelet transform, a data vector X is transformed into a numerically different data vector X’ such that both X and X’ vectors are of the same length. Then how it is useful in reducing data?
The data obtained from the wavelet transform can be truncated. The compressed data is obtained by retaining the smallest fragment of the strongest of wavelet coefficients.
Wavelet transform can be applied to data cube, sparse data or skewed data.
b. Principal Component Analysis
Let us consider we have a data set to be analyzed that has tuples with n attributes, then the principal component analysis identifies k independent tuples with n attributes that can represent the data set.
In this way, the original data can be cast on a much smaller space. In this way, the dimensionality reduction can be achieved. Principal component analysis can be applied to sparse, and skewed data.
c. Attribute Subset Selection
The large data set has many attributes some of which are irrelevant to data mining or some are redundant. The attribute subset selection reduces the volume of data by eliminating the redundant and irrelevant attribute.
The attribute subset selection makes it sure that even after eliminating the unwanted attributes we get a good subset of original attributes such that the resulting probability of data distribution is as close as possible to the original data distribution using all the attributes.
2. Numerosity Reduction
The numerosity reduction reduces the volume of the original data and represents it in a much smaller form. This technique includes two types parametric and non-parametric numerosity reduction.
Parametric
Parametric numerosity reduction incorporates ‘storing only data parameters instead of the original data’. One method of parametric numerosity reduction is ‘regression and log-linear’ method.
- Regression and Log-Linear
Linear regression models a relationship between the two attributes by modelling a linear equation to the data set. Suppose we need to model a linear function between two attributes.
y = wx +b
Here, y is the response attribute and x is the predictor attribute. If we discuss in terms of data mining, the attribute x and the attribute y are the numeric database attributes whereas w and b are regression coefficients.
Multiple linear regression lets the response variable y to model linear function between two or more predictor variable.
Log-linear model discovers the relation between two or more discrete attributes in the database. Suppose, we have a set of tuples presented in n-dimensional space. Then the log-linear model is used to study the probability of each tuple in a multidimensional space.
Regression and log-linear method can be used for sparse data and skewed data.
Non-Parametric
- Histogram
A histogram is a ‘graph’ that represents frequency distribution which describes how often a value appears in the data. Histogram uses the binning method and to represent data distribution of an attribute. It uses disjoint subset which we call as bin or buckets.
We have data for AllElectronics data set, which contains prices for regularly sold items.
1, 1, 5, 5, 5, 5, 5, 8, 8, 10, 10, 10, 10, 12, 14, 14, 14, 15, 15, 15, 15, 15, 15, 18, 18, 18, 18, 18, 18, 18, 18, 20, 20, 20, 20, 20, 20, 20, 21, 21, 21, 21, 25, 25, 25, 25, 25, 28, 28, 30, 30, 30.
The diagram below shows a histogram of equal width that shows the frequency of price distribution.
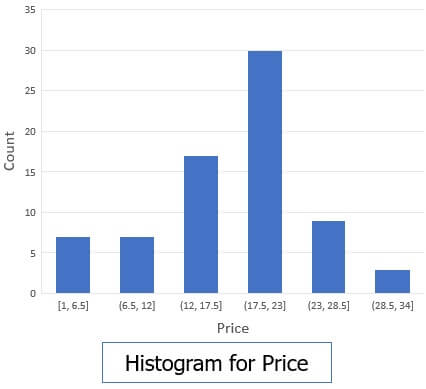 A histogram is capable of representing dense, sparse, uniform or skewed data. Instead of only one attribute, the histogram can be implemented for multiple attributes. It can effectively represent the up to five attributes.
A histogram is capable of representing dense, sparse, uniform or skewed data. Instead of only one attribute, the histogram can be implemented for multiple attributes. It can effectively represent the up to five attributes.
- Clustering
Clustering techniques groups the similar objects from the data in such a way that the objects in a cluster are similar to each other but they are dissimilar to objects in another cluster.
How much similar are the objects inside a cluster can be calculated by using a distance function. More is the similarity between the objects in a cluster closer they appear in the cluster.
The quality of cluster depends on the diameter of the cluster i.e. the at max distance between any two objects in the cluster.
The original data is replaced by the cluster representation. This technique is more effective if the present data can be classified into a distinct clustered.
- Sampling
One of the methods used for data reduction is sampling as it is capable to reduce the large data set into a much smaller data sample. Below we will discuss the different method in which we can sample a large data set D containing N tuples:
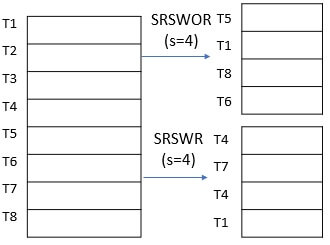
- Simple random sample without replacement (SRSWOR) of size s: In this ‘s number’ of tuples are drawn from N tuples such that in the data set D (s<N). The probability of drawing any tuple from the data set D is 1/N this means all tuples have an equal probability of getting sampled.
- Simple random sample with replacement (SRSWR) of size s: It is similar to the SRSWOR but the tuple is drawn from data set D, is recorded and then replaced back into the data set D so that it can be drawn again.
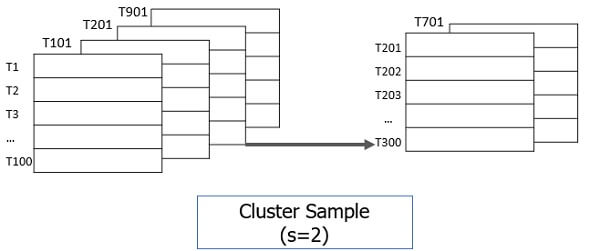
- Cluster sample: The tuples in data set D are clustered into M mutually disjoint subsets. From these clusters, a simple random sample of size s could be generated where s<M. The data reduction can be applied by implementing SRSWOR on these clusters.
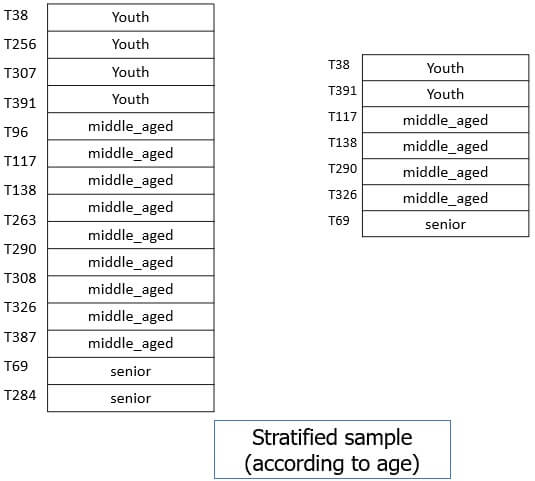
- Stratified sample: The large data set D is partitioned into mutually disjoint sets called ‘strata’. Now a simple random sample is taken from each stratum to get stratified data. This method is effective for skewed data.
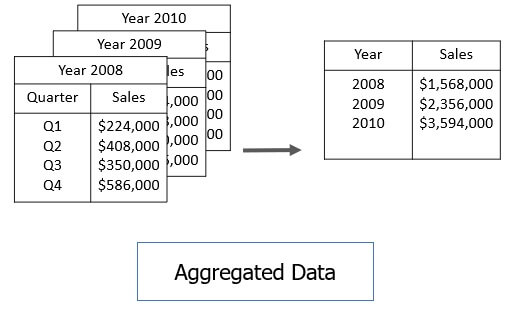
- Data Cube Aggregation
Consider you have the data of AllElectronics sales per quarter for the year 2008 to the year 2010. In case you want to get the annual sale per year then you just have to aggregate the sales per quarter for each year. In this way, aggregation provides you with the required data which is much smaller in size and thereby we achieve data reduction even without losing any data.
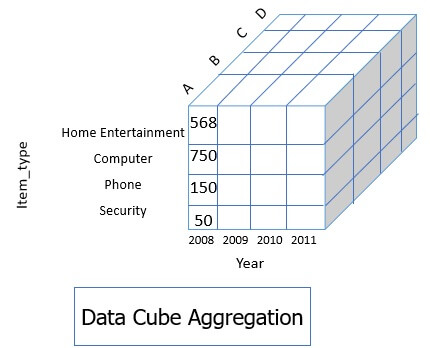
 The data cube aggregation is a multidimensional aggregation which eases multidimensional analysis. Like in the image below the data cube represent annual sale for each item for each branch. The data cube present precomputed and summarized data which eases the data mining into fast access.
The data cube aggregation is a multidimensional aggregation which eases multidimensional analysis. Like in the image below the data cube represent annual sale for each item for each branch. The data cube present precomputed and summarized data which eases the data mining into fast access.
3. Data Compression
Data compression is a technique where the data transformation technique is applied to the original data in order to obtain compressed data. If the compressed data can again be reconstructed to form the original data without losing any information then it is a ‘lossless’ data reduction.
If you are unable to reconstruct the original data from the compressed one then your data reduction is ‘lossy’. Dimensionality and numerosity reduction method are also used for data compression.
Key Takeaways
- Data reduction is a method of reducing the volume of data thereby maintaining the integrity of the data.
- There are three basic methods of data reduction dimensionality reduction, numerosity reduction and data compression.
- The time taken for data reduction must not be overweighed by the time preserved by data mining on the reduced data set.
So, this is all about the data reduction and its techniques. We have covered different methods that can be employed for data reduction.
Leave a Reply