Vector processing performs the arithmetic operation on the large array of integers or floating-point number. Vector processing operates on all the elements of the array in parallel providing each pass is independent of the other.
Vector processing avoids the overhead of the loop control mechanism that occurs in general-purpose computers.
In this section, we will have a brief introduction on vector processing, its characteristics, about vector instructions and how the performance of the vector processing can be enhanced? So lets us start.
Content: Vector Processing in Computer Architecture
Introduction
We need computers that can solve mathematical problems for us which include, arithmetic operations on the large arrays of integers or floating-point numbers quickly. The general-purpose computer would use loops to operate on an array of integers or floating-point numbers. But, for large array using loop would cause overhead to the processor.
To avoid the overhead of processing loops and fasten the computation, some kind of parallelism must be introduced. Vector processing operates on the entire array in just one operation i.e. it operates on elements of the array in parallel. But, vector processing is possible only if the operations performed in parallel are independent.
Look at the figure below, and compare the vector processing with the general computer processing, you will notice the difference. Below, instructions in both the blocks are set to add two arrays and store the result in the third array. Vector processing adds both the array in parallel by avoiding the use of the loop.
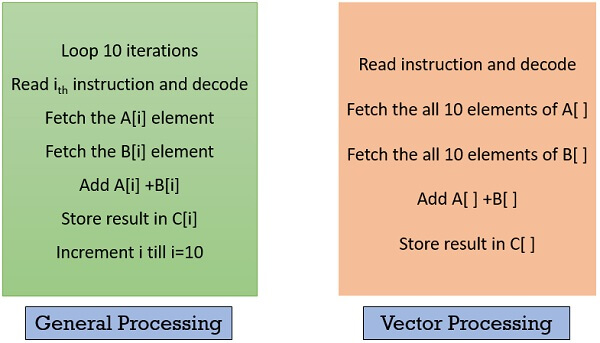
Operating on multiple data in just one instruction is also called Single Instruction Multiple Data (SIMD) or they are also termed as Vector instructions. Now, the data for vector instruction are stored in vector registers.
Each vector register is capable of storing several data elements at a time. These several data elements in a vector register is termed as a vector operand. So, if there are n number of elements in a vector operand then n is the length of the vector.
Supercomputers were evolved to deal with billions of floating-point operations/second. Supercomputer optimizes numerical computations (vector computations).
But, along with vector processing supercomputers are also capable of doing scalar processing. Later, Array processor was introduced which particularly deals with vector processing, they do not indulge in scalar processing.
Characteristics of Vector Processing
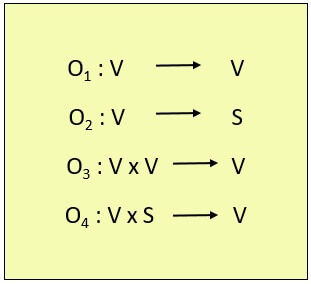
Each element of the vector operand is a scalar quantity which can either be an integer, floating-point number, logical value or a character. Below we have classified the vector instructions in four types.
Here, V is representing the vector operands and S represents the scalar operands. In the figure below, O1 and O2 are the unary operations and O3 and O4 are the binary operations.
Most of the vector instructions are pipelined as vector instruction performs the same operation on the different data sets repeatedly. Now, the pipelining has start-up delay, so longer vectors would perform better here.
The pipelined vector processors can be classified into two types based on from where the operand is being fetched for vector processing. The two architectural classifications are Memory-to-Memory and Register-to-Register.
In Memory-to-Memory vector processor the operands for instruction, the intermediate result and the final result all these are retrieved from the main memory. TI-ASC, CDC STAR-100, and Cyber-205 use memory-to-memory format for vector instructions.
In Register-to-Register vector processor the source operands for instruction, the intermediate result, and the final result all are retrieved from vector or scalar registers. Cray-1 and Fujitsu VP-200 use register-to-register format for vector instructions.
Vector Instruction
A vector instruction has the following fields:
1. Operation Code
Operation code indicates the operation that has to be performed in the given instruction. It decides the functional unit for the specified operation or reconfigures the multifunction unit.
2. Base Address
Base address field refers to the memory location from where the operands are to be fetched or to where the result has to be stored. The base address is found in the memory reference instructions. In the vector instruction, the operand and the result both are stored in the vector registers. Here, the base address refers to the designated vector register.
3. Address Increment
A vector operand has several data elements and address increment specifies the address of the next element in the operand. Some computer stores the data element consecutively in main memory for which the increment is always 1. But, some computers that do not store the data elements consecutively requires the variable address increment.
4. Address Offset
Address Offset is always specified related to the base address. The effective memory address is calculated using the address offset.
5. Vector Length
Vector length specifies the number of elements in a vector operand. It identifies the termination of a vector instruction.
Improving Performance
In vector processing, we come across two overheads setup time and flushing time. When the vector processing is pipelined, the time required to route the vector operands to the functional unit is called Set up time. Flushing time is a time duration that a vector instruction takes right from its decoding until its first result is out from the pipeline.
The vector length also affects the efficiency of processing as the longer vector length would cause overhead of subdividing the long vector for processing.
For obtaining the better performance the optimized object code must be produced in order to utilize pipeline resources to its maximum.
1. Improving the vector instruction
We can improve the vector instruction by reducing the memory access, and maximize resource utilization.
2. Integrate the scalar instruction
The scalar instruction of the same type must be integrated as a batch. As it will reduce the overhead of reconfiguring the pipeline again and again.
3. Algorithm
Choose the algorithm that would work faster for vector pipelined processing.
4. Vectorizing Compiler
A vectorizing compiler must regenerate the parallelism by using the higher-level programming language. In advance programming, the four-stage are identified in the development of the parallelism. Those are
- Parallel Algorithm(A)
- High-level Language(L)
- Efficient object code(O)
- Target machine code (M)
You can see a parameter in the parenthesis at each stage which denotes the degree of parallelism. In the ideal situation, the parameters are expected in the order A≥L≥O≥M.
Key Takeaways
- Computers having vector instruction are vector processors.
- Vector processor have the vector instructions which operates on the large array of integer or floating-point numbers or logical values or characters, all elements in parallel. It is called vectorization.
- Vectorization is possible only if the operation performed in parallel are independent of each other.
- Operands of vector instruction are stored in the vector register. A vector register stores several data elements at a time which is called vector operand.
- A vector operand has several scalar data elements.
- A vector instruction needs to perform the same operation on the different data set. Hence, vector processors have a pipelined structure.
- Vector processing ignores the overhead caused due to the loops while operating on an array.
So, this is how vector processing allows parallel operation on the large arrays and fasten the processing speed.
Md. Fokhray Hossain says
The content is very informative about Vector Processing.