Bottom-Up parsing is applied in the syntax analysis phase of the compiler. Bottom-up parsing parses the stream of tokens from the lexical analyzer. And after parsing the input string it generates a parse tree.
The bottom-up parser builds a parse tree from the leaf nodes and proceeds towards the root node of the tree. In this section, we will be discussing bottom-up parsing along with its types.
What is Bottom-Up Parsing?
Bottom-up parsing pareses the input string from the lexical analyzer. And if there is no error in the input string it constructs a parse tree as output. The bottom-up parsing starts building parse trees from the leaf nodes i.e., from the bottom of the tree. And gradually proceeds upwards to the root of the parse tree.
The bottom-up parsers are created for the largest class of LR grammars. As the bottom-up parsing corresponds to the process of reducing the string to the starting symbol of the grammar.
Step of Reducing a String:
- A specific substring from the input string is identified.
- A non-terminal in a grammar whose production body matches the substring is identified.
- The substring in the input string is replaced by the non-terminal identified in step 2.
The main problem of bottom-up parsing is to decide:
-
When to reduce which substring from the input string.
-
Which production from the grammar must be applied.
The reduction process is just the reverse of derivation that we have seen in top-down parsing. Thus, the bottom-up parsing derives the input string reverse.
Shift Reduce Parsing
Shift reduce parsing is the most general form of bottom-up parsing. Here we have an input buffer that holds the input string that is scanned by the parser from left to right. There is also a stack that is used to hold the grammar symbols during parsing.
The bottom of the stack and the right end of the input buffer is marked with the $. Initially, before the parsing starts:
-
The input buffer holds the input string provided by the lexical analyzer.
-
The stack is empty.
As the parser parses the string from left to right then it shifts zero or more input symbols onto the stack.
The parser continues to shift the input symbol onto the stack until it is filled with a substring. A substring that matches the production body of a nonterminal in the grammar. Then the substring is replaced or reduced by the appropriate nonterminal.
The parser continues shift-reducing until either of the following condition occurs:
- It identifies an error
- The stack contains the start symbol of the grammar and the input buffer becomes empty.
To perform the shift-reduce parsing we have to perform the following four functions.
Four Functions of Shift Reduce Parsing:
- Shift: This action shifts the next input symbol present on the input buffer onto the top of the stack.
- Reduce: This action is performed if the top of the stack has an input symbol that denotes a right end of a substring. And within the stack there exist the left end of the substring. The reduce action replaces the entire substring with the appropriate non-terminal. The production body of this non-terminal matches the replaced substring.
- Accept: When at the end of parsing the input buffer becomes empty. And the stack has left with the start symbol of the grammar. The parser announces the successful completion of parsing.
- Error: This action identifies the error and performs an error recovery routine.
Let us take an example of the shift-reduce parser. Consider that we have a string id * id + id and the grammar for the input string is:
E ->E + T | T
T -> T * F | F
F -> ( E ) | id
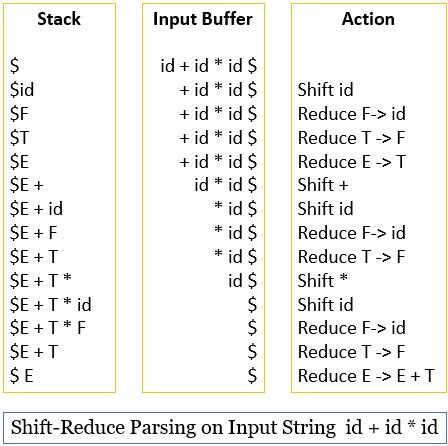
Note: In the shift-reduce parsing a handle always appears on the top of the stack. The handle is a substring that matches the body of production in the grammar. The handle must never appear inside the stack.
Bottom-Up Parsing in LR Parser
The bottom-up parsing is based on the concept of LR(K) parsing.
- L stands for left-to-right parsing of the input string.
- R stands for construction of the rightmost derivation in reverse.
- K stands for the number of input symbols that the parser will look ahead for making a parsing decision.
The LR parser has the following structure:
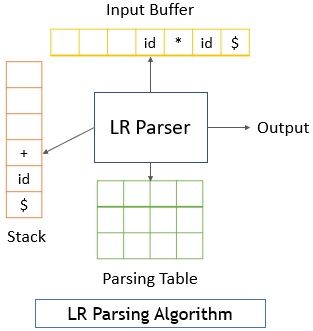
Similar to predictive parsing the end of the input buffer and end of stack has $.
-
The input buffer has the input string that has to be parsed.
-
The stack maintains the sequence of grammar symbols while parsing the input string.
-
The parsing table is a two-dimensional array that has two entries ‘Go To’ and ‘Action’.
The LR parsing can be classified as:
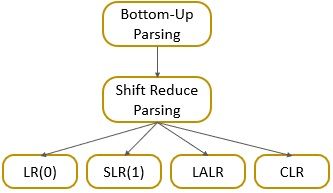
- LR(0) Parsing
- Simple LR Parsing (SLR)
- Canonical LR Parsing (CLR)
- Look-Ahead LR Parsing (LALR)
All kinds of LR parsers are the same they only differ in the construction of their parsing table. We will discuss each of them in brief in our future contents.
So, this is all about the Bottom-Up parsing. We have discussed the most general form of bottom-up parsing i.e., shift-reduce bottom-up parsing along with an example. We have discussed the structure of the LR parser and its types.
Leave a Reply