Context-free grammar (CFG) is a set of production rules that generates context-free language. In this context, we will be learning about the ambiguity in the CFG, its simplification, and its applications.
Content: Context-free Grammar
- What is Context-free Grammar?
- Notational Conventions of CFG
- Ambiguity in Context-free Grammar
- Simplification of Context-free Grammar
- Applications of Context-free Grammar
What is Context-free Grammar?
Grammar is a set of production rules that defines the syntax of a language. We can define context-free grammar under the following four components:
- Terminals: A set of terminals which we also refer to as tokens, these set of tokens forms strings.
- Non-Terminals: CFG has a set of non-terminals (variables). These variables represent the set of strings. Further, they contribute to the formation of a language generated by grammar.
- Start Symbol: A grammar has a set of production rules that has only one start symbol. This start symbol is always a nonterminal. Starting from the start symbol we can generate the set of strings. And this set of strings contributes to generating a language.
- Production: A grammar has a set of production rules. These rules specify how to combine terminals and non-terminals to form a string. The set of strings further helps in the formation of language. A production rule must have:
- A nonterminal which is also referred to as the head always lies at the left side of the production.
- A production rule consists of the symbol (arrow) ‘->’ or sometimes ‘: = ‘. The arrow points towards the body of the production rule for the particular non-terminal.
- The body of the production rule occurs at the right side of the production. We can have zero or more terminals and non-terminals in the body of any production. It is the body of the production rule that describes the formation of strings.
Example of Context-free Grammar:
Let us consider a grammar production
The production rule above specifies the structure of a conditional statement. From the production rule above:
- The ‘stmt’ and ‘expr’ are the non-terminals in the production above.
- The keywords ‘if’ and ‘else’, and the symbols ‘(’ and ‘)’ are the tokens or terminals in the production above.
- In the production rule above the start symbol is the nonterminal ‘stmt’.
Notational Conventions of CFG
It is not always specified that for the following grammar, these are ‘terminals’ and these are ‘non-terminals’. So, for convenience there must be some notational conventions as discussed below:
For Terminals:
- We refer to the lowercase characters like a, b, c, etc. as the terminals.
- Operators symbols like ‘+’, ‘*’, ‘-’ etc are also terminals.
- The tokens such as the punctuation marks such as comma, parenthesis, semicolon etc.
Digits present in the grammar are also considered as tokens. - Bold style strings such as ‘id’, ‘if’, ‘else’ are also terminals.
For Non-Terminals:
- We refer to the uppercase characters like ‘V’, ‘T’, ‘S’. as non-terminals.
- Usually, we refer to the letter ‘S’ as a start symbol in grammar.
- Lowercase italic string is such as ‘stmt’ or ‘expr’.
Ambiguity in Context-free Grammar
In grammar, if one production rule produces more than one parse tree, then the grammar is ambiguous. The grammar is even ambiguous if it is able to produce more than one left-most derivation. We can even refer to the grammar as ambiguous if it produced more than one right-most derivation.
To understand this let us overview an example, consider the arithmetic expression grammar:
For the input statement, id + id * id the grammar is able to produce two distinct left-most derivations. Observe the figure below:
The first leftmost derivation for the above grammar is:
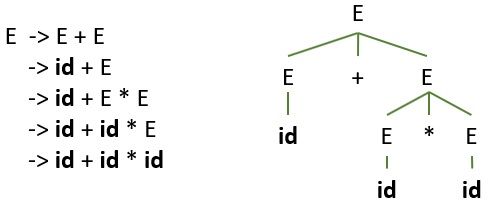
The second left-most derivation for the above grammar is:
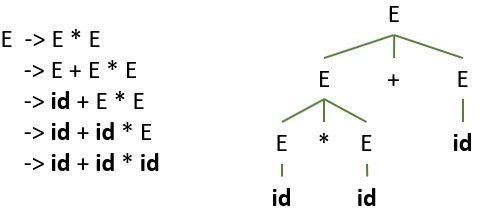
Thus we can declare the grammar above is ambiguous. As the grammar is producing two distinct left-most derivations for one production rule.
An unambiguous grammar is always advantageous for the parser. As there will be no need to identify which parse tree to consider for the given input statement.
You can choose ambiguous grammar along with disambiguating rules. These rules help in eliminating the undesirable parse trees. Thus it leaves a single parse tree for an input statement.
Simplification of CFG
The context-free grammar is not always optimized. There may be some productions in the grammar that are redundant and not useful at all. These redundant productions only increase the size of the grammar.
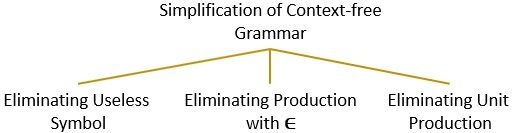
We can simplify the context-free grammar by eliminating these redundant productions. Such that the simplified CFG must be equivalent to the original CFG. The simplified CFG must have the following properties::
- Each non-terminal or terminal in simplified CFG must appear in the formation of some sentence from the language.
- Simplified CFG must not consist of the production where a non-terminal produces a non-terminal only such as A -> B.
- If there is no ∈ in the language then there should not be any product that tends to ∈.
1. Eliminating Useless Symbols
We refer to a symbol or variable as useless if it doesn’t appear on the right side of any production rule of the grammar. They are useless even if it doesn’t contribute in deriving any string.
Example:
A -> aA
B -> ab|d
C -> ab
In the above grammar, we cannot use the variable ‘C’ in deriving any string. As we can not reach variable ‘C’ from the starting symbol T. So we can eliminate the production C -> ab.
Observe that the variable A in the grammar above is useless. As there is no way to terminate the symbol ‘A’. Thus, it will never produce a string. So, we must eliminate production A -> aA such that no variable should lead to a string consisting of variable A.
So, the modified grammar is:
B -> ab|d
2. Eliminate Production with ∈
To simplify CFG we need to eliminate the production such as A -> ∈ also referred to as null productions. We can eliminate such production if the grammar does not generate an empty string. It is possible for a grammar to contain null production and yet does not produce an empty string.
Steps to remove null productions:
- Identify all the non-terminals that derive ∈.
- Construct all the production for the non-terminals (identified in step 1) by substituting ∈.
- Now integrate the results of step 2 with original grammar. And eliminate ∈ from the production.
Example: Consider the grammar
A → aA | ∈
B → bB | ∈
From the productions above we have to eliminate A -> ∈ and B -> ∈ such that the meaning of the original CFG is still preserved. Let us take the first production with the starting symbol S:
First, we will substitute A -> ∈ at first A of the production body. It results in:
Now, substitute A -> ∈ at last A of the production it would result in:
Now if we substitute B -> ∈
If A -> ∈ and B -> ∈ then
If both As are replaced by ∈
Now we will integrate the result with the original production rule of variable S.
Similarly, we will replace ∈ in the production:
If A -> ∈ then
So, the original production we will appear as
Similarly, for B -> bB
At last the grammar after eliminating ∈ from the original grammar it appears as:
A -> aA | a
B -> bB | b
3. Eliminating Unit Productions
In a unit production, a non-terminal tends to another non-terminal such as A -> B.
Example:
A -> b | B
B -> A | a
The unit productions that we have in the original grammar are:
A -> B
B -> A
To eliminate unit productions, replace the non-terminal at the right side of the production with terminals. It will result in:
A -> a
B -> b
Now integrate the improvised unit production to the original grammar.
A -> b | a
B -> b | a
The symbol ‘B’ in the above grammar is useless. Because, there is no way to reach symbol ‘B’ from the starting symbol S. So, further we will eliminate symbol B.
Thus, the resultant CFG would be:
A -> b | a
Applications of CFG
- As CFG can efficiently describe a programming language. We can turn context-free grammar into a parser.
- CFG is helpful in describing the document type definition DTD in XML.
So, this is all about the context-free grammar CFG. We have learnt about CFG, ambiguous CFG, simplification of CFG and applications of CFG.
Leave a Reply