Top-down parsing processes the input string provided by a lexical analyzer. And generate a parse tree for that input string using leftmost derivation. The top-down parsing first creates the root node of the parse tree. And it continues creating its leaf nodes.
Remember the top-down parsing cannot handle the grammar with left recursion and ambiguity.
In this section, we will be learning more about top-down parsing, its key problem, its types and its advantages and disadvantages.
Content: Top-Down Parsing
- What is Top-Down Parsing?
- Key Problems in Top-Down Parsing
- Types of Top-Down Parsing
- Advantages and Disadvantages
What is Top-Down Parsing?
Top-down parsing is a method of parsing the input string provided by the lexical analyzer. The top-down parser parses the input string and then generates the parse tree for it.
Construction of the parse tree starts from the root node i.e. the start symbol of the grammar. Then using leftmost derivation it derives a string that matches the input string.
In the top-down approach construction of the parse tree starts from the root node and end up creating the leaf nodes. Here the leaf node presents the terminals that match the terminals of the input string.
- To derive the input string, first, a production in grammar with a start symbol is applied.
- Now at each step, the parser has to identify which production rule of a non-terminal must be applied in order to derive the input string.
- The next step is to match the terminals in the production with the terminals of the input string.
Example of Top-Down Parsing
Consider the input string provided by the lexical analyzer is ‘abd’ for the following grammar.
A -> b | b c
The top-down parser will parse the input string ‘abd’ and will start creating the parse tree with the starting symbol ‘S‘.
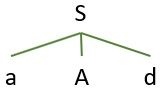
Now the first input symbol ‘a‘ matches the first leaf node of the tree. So the parser will move ahead and find a match for the second input symbol ‘b‘.
But the next leaf node of the tree is a non-terminal i.e., A, that has two productions. Here, the parser has to choose the A-production that can derive the string ‘abc‘. So the parser identifies the A-production A-> b.
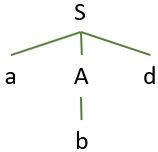 Now the next leaf node ‘b‘ matches the second input symbol ‘b‘. Further, the third input symbol ‘d‘ matches the last leaf node ‘d‘ of the tree. Thereby successfully completing the top-down parsing
Now the next leaf node ‘b‘ matches the second input symbol ‘b‘. Further, the third input symbol ‘d‘ matches the last leaf node ‘d‘ of the tree. Thereby successfully completing the top-down parsing
Key Problems of Top-Down Parser
Top-down parsing determines the leftmost derivation for the provided input string. At each step of parsing a production of a non-terminal is chosen to derive the input string.
The key problem in top-down parsing is to identify which production of a non-terminal must be chosen. Such that the terminals in the production body match the terminals in the input string.
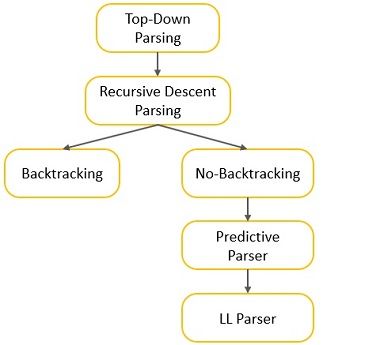
Types of Top-Down Parser
In this section, we will be discussing various forms of top-down parsing. The most general form of top-down parsing is recursive descent parsing.
We can perform recursive descent parsing in two ways:
- One which requires backtracking.
- Other which requires no backtracking.
The method that doesn’t need backtracking is referred to as predictive parsing. The figure below illustrates various forms of top-down parsing.
Recursive Descent Parsing
A recursive descent parsing program has a set of procedures. There is one procedure for each of the non-terminal present in the grammar. The parsing starts with the execution of the procedure meant for the starting symbol.
void A() {
1) Choose an A-production, A-> X1 X2 … Xk;
2) for (i = 1 to k) {
3) if (Xi is a nonterminal)
4) call procedure Xi();
5) else if (Xi = current input symbol a)
6) advance the input to the next symbol;
7) else /* an error has occurred */;
}
}
The pseudocode above expresses the procedure for a typical non-terminal. This pseudocode is non-deterministic. This is because it doesn’t specify the method in which the production of a non-terminal must be applied.
In the recursive descent parsing, there may be some cases where we may need backtracking. Backtracking is scanning the provided input string by parser repeatedly.
Backtracking in Top-Down Parsing
If one production of a non-terminal fails in deriving the input string. The parser has to go back to the position where it has chosen the production. And start deriving the string again using another production of the same nonterminal. This process may need repeated scans over the input string and we refer to it as backtracking.
To allow backtracking the above pseudocode requires the following modifications.
- Instead of choosing a unique A production at line 1, we must try each of several productions in grammar in some order.
- The failure declared at line 7 is not an ultimate failure. Hence, it must suggest to return to line 1 again and apply another A production.
And if no more A productions are left to apply then it must declare an error in the input string. - To try another A production, there must be some means to reset the input pointer. That means the input pointer must point back at the position where it was first when we have executed line 1.
For this, we must declare a local variable. This local variable stores the value of the input pointer that helps in backtracking.
Example of Recursive Descent Top-Down Parsing
A -> b | b c
For the above grammar, the input string provided to the parser is ‘abcd’.
We will start building the parse tree with the start symbol S and the input pointer points to the first symbol of the input string i.e. ‘a’. As the start symbol ‘S’ has only one production in its production’s body. So, we will expand the symbol ‘S’.
The leftmost leaf ‘a’ of the tree matches the first symbol of the input string i.e. ‘a’. Thus, we will advance the input pointer to the next symbol of the input string i.e. ‘b’.
Now the next leaf of the parse tree is ‘A’. Symbol A has two production rules. Expanding symbol ‘A’ with the first production of ‘A’ i.e., symbol ‘b’ we get the following parse tree.
Here, we have the match for the second input symbol, ‘b’. So, we will advance the input pointer to point next symbol of the input string i.e. ‘c’.
Now, when we compare the third input symbol ‘c’ against the next leaf labelled ‘d’ we get a mismatch. So, the parser needs to go back to the symbol ‘A’ and look for the other alternative.
The other alternative for the production of ‘A’ is ‘bc’. Also, the input pointer has to be backtracked and must be reset to the position where it was first before we expanded the symbol ‘A’. That means the input pointer must point to ‘b’ again.
We will again expand ‘A’ with the next alternative production. Now the leaf of the parse tree label ‘b’ matches the second input symbol ‘b’.
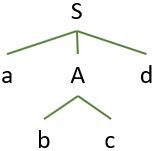
So, the input pointer is advanced and it points to the third input symbol ‘c’. The next leaf of the tree labelled ‘c’ matches the third input symbol.
Further, the input pointer is advanced to point to the fourth input symbol ‘d’. This matches the next leaf of the tree labelled ‘d’.
Thus, the parser has produced a parse tree for the provided input string and this completes the parsing process successfully.
Predictive Parsing
Predictive parsing is a simple form of recursive descent parsing. And it requires no backtracking. Instead, it can determine which A-production must be chosen to derive the input string.
Predictive parsing chooses the correct A-production by looking ahead at the input string. It allows looking ahead a fixed number of input symbols from the input string.
Components of Predictive top-down Parser
Predictive top-down parsing program maintains three components:
- Stack: A predictive parser maintains a stack containing a sequence of grammar symbols.
- Input Buffer: It contains the input string that the predictive parser has to parse.
- Parsing Table: With the entries of this table it becomes easy for the top-down parser to choose the production to be applied.
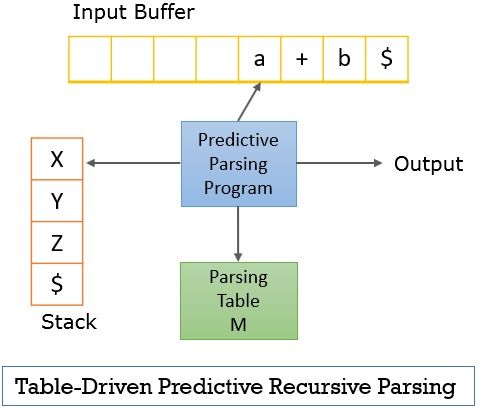
Input buffer and stack both contain the end marker ‘$’. It indicates the bottom of the stack and the end of the input string in the input buffer.
Initially, the grammar symbol on the top of $ is the start symbol. The pseudocode below shows you the working of the predictive top-down parser.
let a be the first symbol of w;
let X be the top stack symbol;
while (X ≠$) f /* stack is not empty */
if (X = a) pop the stack and let a be the next symbol of w;
else if (X is a terminal) error ();
else if (M[X; a] is an error entry ) error();
else if (M[X; a] = X ->| Y1Y2 _ _ _ Yk ){
output the production X -> Y1Y2 _ _ _ Yk;
pop the stack;
push Yk, Yk-1; : : : ; Y1 onto the stack, with Y1 on top;
}
let X be the top stack symbol;
}
Steps to perform predictive parsing:
- The parser first considers the grammar symbol present on the top of the stack say ‘X’. And compares it with the current input symbol say ‘a’ present in the input buffer.
- If X is a non-terminal then the parser chooses a product of X from the parse table, consulting the entry M [X, a].
- In case, X is a terminal then the parser checks it for a match with the current symbol ‘a’.
This is how predictive parsing identifies the correct production. So that it can successfully derive the input string.
LL Parsing
The LL parser is a predictive parser that doesn’t need backtracking. LL (1) parser accepts only LL (1) grammar.
- First L in LL (1) indicates that the parser scans the inputs string from left to right.
- Second L determines the leftmost derivation for the input string.
- The ‘1’ in LL (1) indicates that the parser lookahead only one input symbol from the input string.
LL (1) grammar does not include left recursion and there is no ambiguity in the LL (1) grammar.
Advantages of Top-Down Parsing
Advantages
- Top-down parsing is very simple.
- It is very easy to identify the action decision of the top-down parser.
Disadvantages
- Top-down parsing is unable to handle left recursion in the present in the grammar.
- Some recursive descent parsing may require backtracking.
This is all about top-down parsing. We have learnt how top-down parsing is performed, its various types. We have also studied the key problem of top-down parsing. And we have also learnt the term backtracking required in some cases of top-down parsing.
Leave a Reply