Specification of tokens depends on the pattern of the lexeme. Here we will be using regular expressions to specify the different types of patterns that can actually form tokens.
Although the regular expressions are inefficient in specifying all the patterns forming tokens. Yet it reveals almost all types of pattern that forms a token.
Content: Specification of Tokens
String and Languages
String
The string is a finite set of alphabets. Alphabet is a finite set of symbols. Symbols can be letters, digits and punctuation.
Example 1:
The set of digits (symbols) {0, 1} forms a binary alphabet. As there are only two symbols to form an alphabet.
If you can remember ASCII system that is used in almost every computer, denotes the alphabet A using the set of digits {0, 1} i.e. A = 01000001.
Example 2:
The Unicode system defines an alphabet by assigning a unique number to each alphabet. On average, it has 100000 alphabets from around the world including emojis.
Length of String
The length of the string can be determined by the number of alphabets in the string. The string is represented by the letter ‘s’ and |s| represents the length of the string. Let’s consider the string:
s = banana|s| = 6
Note: The empty string or the string with length 0 is represented by ‘∈’.
Language
Language is a set of strings over some fixed alphabets. Like the English language is a set of strings over the fixed alphabets ‘a to z’.
Terms Related to String
1. Prefix of String
The prefix of the string is the preceding symbols present in the string and the string s itself.
For example:
s = abcd
The prefix of the string abcd: ∈, a, ab, abc, abcd
2. Suffix of String
Suffix of the string is the ending symbols of the string and the string s itself.
For example:
s = abcd
Suffix of the string abcd: ∈, d, cd, bcd, abcd
3. Proper Prefix of String
The proper prefix of the string includes all the prefixes of the string excluding ∈ and the string s itself.
Proper Prefix of the string abcd: a, ab, abc
4. Proper Suffix of String
The proper suffix of the string includes all the suffixes excluding ∈ and the string s itself.
Proper Suffix of the string abcd: d, cd, bcd
5. Substring of String
The substring of a string s is obtained by deleting any prefix or suffix from the string.
Substring of the string abcd: ∈, abcd, bcd, abc, …
6. Proper Substring of String
The proper substring of a string s includes all the substrings of s excluding ∈ and the string s itself.
Proper Substring of the string abcd: bcd, abc, cd, ab…
7. Subsequence of String
The subsequence of the string is obtained by eliminating zero or more (not necessarily consecutive) symbols from the string.
A subsequence of the string abcd: abd, bcd, bd, …
8. Concatenation of String
If s and t are two strings, then st denotes concatenation.
s = abct = def
Concatenation of string s and t i.e. st = abcdef
Operation on Languages
As we have learnt language is a set of strings that are constructed over some fixed alphabets. Now the operation that can be performed on languages are:
1. Union
Union is the most common set operation. Consider the two languages L and M. Then the union of these two languages is denoted by:
That means the string s from the union of two languages can either be from language L or from language M.
If L = {a, b} and M = {c, d}Then L ∪ M = {a, b, c, d}
2. Concatenation
Concatenation links the string from one language to the string of another language in a series in all possible ways. The concatenation of two different languages is denoted by:
L ⋅ M = {st | s is in L and t is in M}If L = {a, b} and M = {c, d}
Then L ⋅ M = {ac, ad, bc, bd}
3. Kleene Closure
Kleene closure of a language L provides you with a set of strings. This set of strings is obtained by concatenating L zero or more time. The Kleene closure of the language L is denoted by:
If L = {a, b}L* = {∈, a, b, aa, bb, aaa, bbb, …}
4. Positive Closure
The positive closure on a language L provides a set of strings. This set of strings is obtained by concatenating ‘L’ one or more times. It is denoted by:
It is similar to the Kleene closure. Except for the term L0, i.e. L+ excludes ∈ until it is in L itself.
If L = {a, b}L+ = {a, b, aa, bb, aaa, bbb, …}
So, these are the four operations that can be performed on the languages in the lexical analysis phase.
Regular Expression
A regular expression is a sequence of symbols used to specify lexeme patterns. A regular expression is helpful in describing the languages that can be built using operators such as union, concatenation, and closure over the symbols.
A regular expression ‘r’ that denotes a language L(r) is built recursively over the smaller regular expression using the rules given below.
The following rules define the regular expression over some alphabet Σ and the languages denoted by these regular expressions.
- It ∈ is a regular expression that denotes a language L(∈). The language L(∈) has a set of strings {∈} which means that this language has a single empty string.
- If there is a symbol ‘a’ in Σ then ‘a’ is a regular expression that denotes a language L(a). The language L(a) = {a} i.e. the language has only one string of length one and the string holds ‘a’ in the first position.
- Consider the two regular expressions r and s then:
- r|s denotes the language L(r) ∪ L(s).
- (r) (s) denotes the language L(r) ⋅ L(s).
- (r)* denotes the language (L(r))*.
- (r)+ denotes the language L(r)
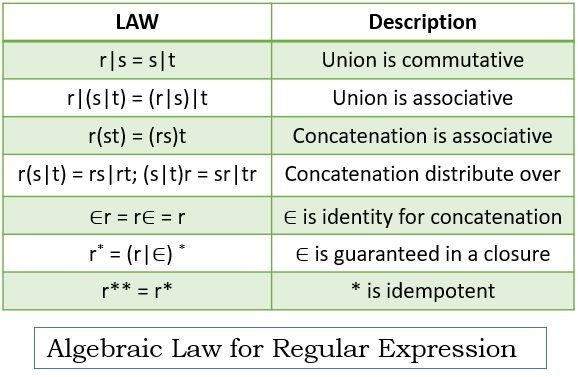
Algebraic Law for Regular Expression
Consider the regular expressions r, s, t. Algebraic laws for these regular expressions.
Regular Definition
The regular definition is the name given to the regular expression. The regular definition (name) of a regular expression is used in the subsequent expressions. The regular definition used in an expression appears as if it is a symbol.
If Σ = alphabet of the basic symbol
Then regular definition is a sequence of definitions of the form.
d1 -> r1d2 -> r2
…
dn -> rn
Each definition i.e. each di is a new symbol and is not present in Σ. Each of the d’s is unique.
Here ri is the regular expression over the alphabet ‘Σ ∪ {d1, d2, …, di-1}’.
Till now we have studied the regular expression with the basic operand’s union, concatenation and closure. The regular expression can be further extended to specify string patterns.
1. One or more instances
The unary postfix operator + denotes the positive closure which means one or more occurrences of the expression.
If ‘r’ is a regular expression, the r+ denotes the language (L(r))+.
The precedence and associativity of the operator + are the same as the operator *. The algebraic law representing the relation between Kleene closure (*) and the positive closure (+) is:
r* = r+ | ∈r+ = rr* = r*r
2. Zero or one Instance
The unary postfix operator ‘?’ denotes zero or one occurrence of the regular expression r.
r? = r |∈L(r?) = L(r) ∪ L(∈)
3. Character classes
Consider a regular expression a1| a2| …| an.
Now here each ai is the symbol of the alphabet you can replace them by shorthand [a1, a2, … an] or by [a1 – an].
So, this is all about how regular expressions helps in the specification of tokens. We have learnt about how regular expression denotes a regular language. We have even discussed regular expressions and regular language.
Leave a Reply