Finite automata (FA) can be defined as a recognizer that identifies whether the input string represents the regular language. The finite automata accept the input string if the input string is a regular expression representing the regular language else it rejects it.
In this section, we will discuss the finite automata, their types, how can we convert them into regular expressions and vice versa. Ahead we will learn to minimize finite automata, about their limitations and their advantages.
Content: Finite Automata in Compiler Design
- What are Finite Automata?
- Types of Finite Automata
- Finite Automata to Regular Expression
- Regular Expression to Finite Expression
- Block Diagram
- Minimization
- Limitations
- Applications
What are Finite Automata in Compiler Design?
Finite automata is a finite state machine that acts as a recognizer for a language. When it is provided with an input string it accepts or rejects the string based on whether the string is from the language or not.
FA recognize the regular expression that is a set of strings and accepts it if it represents a regular language else it rejects it. When finite automata accept the regular expression, it compiles it to form a transition diagram.
In finite automata, there is a finite state for each input. FAcan be categorized in two ways deterministic finite automata and non-deterministic finite automata.
Types of FA
There are two kind of FA:
- Deterministic Finite Automata (DFA)
- Non-Deterministic Finite Automata (NFA)
Deterministic FA
In deterministic finite automata in response to a single input alphabet, the state transits to only one state. In DFA, no null moves are accepted.
The DFA have five tuples as discussed below:
{Q, Σ, q0, F, δ}
- Q = set of all states
- Σ = Set of all input alphabets
- q0 = initial state
- F = Set of Final State
- δ = Transition function
The DFA can be represented by the transition graph. In the transition graph, the nodes of the graph represent the states and the edges represent the transition of one state to another. Let us take an example of DFA:
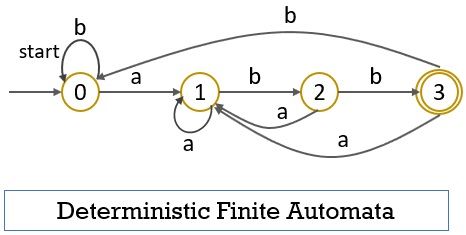
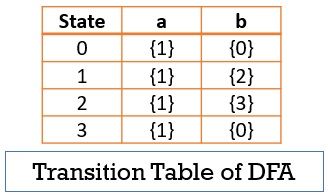
In the above example of DFA, you can notice that with a single input ‘a’ state ‘0’ transit t only one state ‘1’. The transition table for the above DFA is as below:
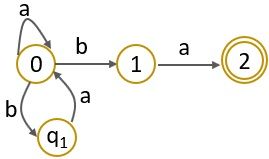
Non-Deterministic FA
In non-deterministic finite automata, in response to a single input alphabet, a state may transit to more than one state. The NFA also accept the NULL move.
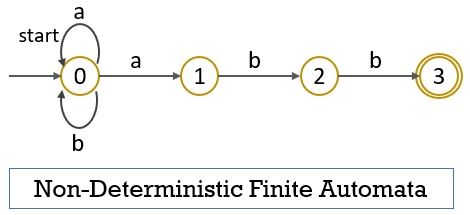
In the above example of NFA, you can notice that the state ‘0’ with the input symbol ‘a’ can either transit to itself or to state ‘1’. Now let us create a transition table for the NFA above.
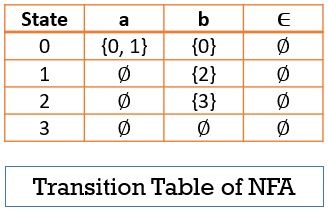
With the transition table, it becomes easy to identify the transition on a given state with the given input. Although it takes a lot of space if there are a lot of input alphabets as most of the state do not perform any transition on most of the input symbols.
Before we learn to convert a regular expression to FA or vice versa let us discuss in detail regular expression.
What is Regular Expression?
A regular expression is a string that represents a regular language. An expression is said to be regular if the string is represented as:
- a*-> it means zero or more occurrence of a
{∈, a, aa, aaa, aaaa…} // here * is a Kleene closure - a+-> it means one or more occurrences of a
{ a, aa, aaa, aaaa…} // here + is a positive closure - a.b -> it means the concatenation i.e. a will be followed by b
- a|b -> it means the union i.e. either ‘a’ will appear or ‘b’
So, this is the way in which the regular expression can represent a regular language. Like we follow the precedence of operators in mathematic like BODMAS. Here also we have precedence of operators in sequence:
- Kleene Closure {a*}
- Positive Closure {a+}
- Concatenation {a.b}
- Union {a|b}
A regular expression is said to be valid we are able to derive the expression using primitive regular expressions using the finite application of rules that are a*, a+, a.b, a|b.
Now, let us first learn to convert finite automata to the regular expression:
Finite Automata to Regular Expression
There are two methods to convert finite automata to the regular expression:
- Ardern’s Method
- State Elimination
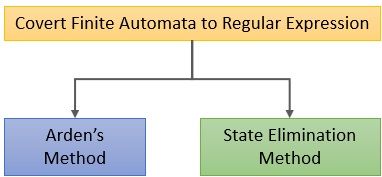
For explanation, we will be only discussing the state elimination method.
State Elimination Method:
Here we will discuss the conversion of DFA to regular expression
Step 1: The initial state of DFA should not have any incoming edge. If there is an incoming edge to the initial state you must create a new initial state.
Step 2: There should not be any outgoing edges from the final state. If the final state has any outgoing edges then make a new final state.
Step 3: There should be only one final state in any automata. If multiple final states exist, they all must be converted to a non-final state and we must create a new final state.
Step 4: Eliminate all the intermediate states such that there will only be one initial state and one final state.
Example
Let us take a finite automaton:
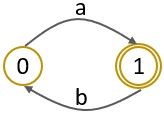
Step 1: As the initial state has an incoming edge we have to create a new initial state.
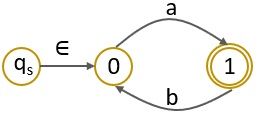
Step 2: As the final state has an outgoing edge then we have to create a new final state.
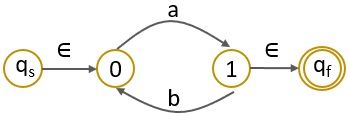
Step 3: Now you have to start eliminating the intermediate states so we have initially eliminated state ‘0’.
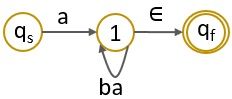
Step 4: Next, we will eliminate the state ‘1’.
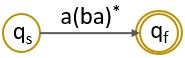
Regular Expression to Finite Automata
Now let us take a regular expression (a+ba)*ba and we will learn to convert it to finite automata.
Example
Step 1:
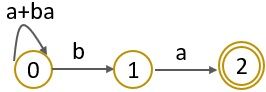
Step 2:
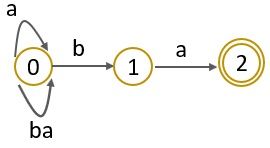
Step 3:
Block Diagram of FA
The concept of FA can be explained with the help of a block diagram as shown in the figure below:
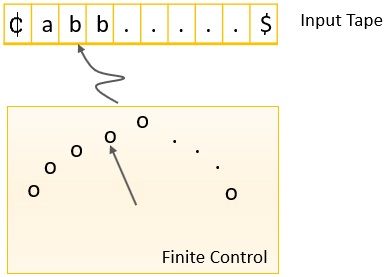
Let us discuss the components of the block diagram of FA :
- Input Tape: The input tape is divided into a number of blocks and has two ends left and right end. The left end is marked with ₵ and the right end of the input tape is marked with the $. Each block of the input tape has a single input symbol. The input tape is of infinite length.
- Read Only Head: The input tape is indexed by a read-only head that point at only one block of input tape at a time. The head always starts reading from the leftmost block of the input tape and move towards the right.
- Finite Control: The finite control block determines the state of finite automata ad also controls the movement of the head reading the input tape.
Minimization of DFA
Minimization of DFA is reducing the DFA to minimum states and keeping it equivalent to the provided DFA. The FA must be containing some redundant states which unnecessarily increases the size of automata. Thus, it is essential to minimize the finite automata.
The number of states in the FA decides the size of the automata. To reduce the size of the automat we must remove all the redundant states that do not affect the language accepted by the finite automata. Let us discuss the steps of minimizing the FA .
- Remove all unreachable states.
- Draw a transition table for all pairs of states.
- Split the set of all states into two i.e., T1 (set of final states) T2 (set of non-final states).
- Identify and merge equivalent state from set T1 and repeat the same for T2.
- Now after merging the equivalent states in T1 and T2 combine the reduced sets T1 and T2.
Example
We will minimize the finite automata shown in the diagram below:
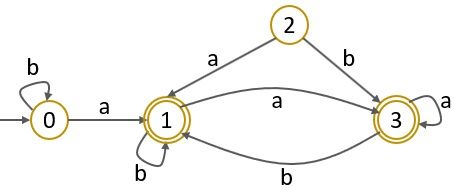
Step 1: In the automata above you can notice that the state ‘2’ is unreachable so we will first remove state ‘2’.
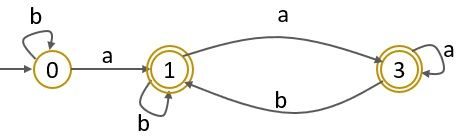
Step 2: Next, we have to create a transition diagram for the automata.
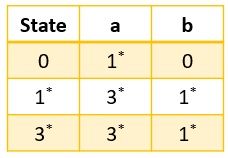
Step 3: Further, we have to make two sets one consisting of the final states and the other consisting the non-final states.

Step 4: As the set with final states has two equivalent rows leading to this we can merge states ‘1,3’.
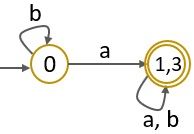
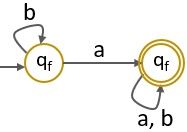
Step 5: The final minimized finite automata are as follow:
Limitations of Finite Automata
- In the FA, as the name includes ‘finite’, it can count only the finite number of states.
- It do not recognize the set of binary strings that has an equal number of 0’s and 1’s.
- It do not even recognize the set of strings over the parenthesis ‘(’ and ‘)’ that have balanced parenthesis.
Applications of Finite Automata
- As FA is a recognizer it is usefully inapplicable while designing the lexical analyser.
- It is even applicable while designing text editors.
- As it recognizes the pattern of the input string it is even used to design the spell checker.
- It is even used to design sequential and combinational circuits.
So, this is all about the finite automata, its type, its conversion to regular expression and vice versa, its minimization, its limitations and applications.
Leave a Reply