Lexical Analysis in compiler is the first step in the analysis of the source program. The lexical analysis reads the input stream from the source program character by character and produces the sequence of tokens. These tokens are provided as an input to the parser for parsing. In this context, we will be discussing the process of lexical analysis in brief along with the lexical errors and their recovery.
Content: Lexical Analysis in Compiler Design
- Terminologies in Lexical Analysis
- What is Lexical Analysis?
- Role of Lexical Analyzer
- Lexical Error
- Error Recovery
- Key Takeaways
Terminologies in Lexical Analysis
Before getting into what lexical analysis is how it is performed let us talk about some terminologies that are we will come across while discussing lexical analysis.
- Lexeme
Lexeme can be defined as a sequence of characters that forms a pattern and can be recognized as a token. - Pattern
After identifying the pattern of lexeme one can describe what kind of token can be formed. Such as the pattern of some lexeme forms a keyword, the pattern of some lexemes forms an identifier. - Token
A lexeme with a valid pattern forms a token. In lexical analysis, a valid token can be identifiers, keywords, separators, special characters, constants and operators.
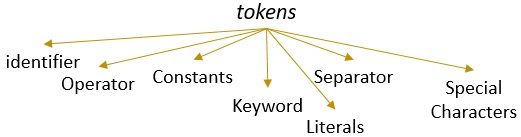
What is Lexical Analysis?
Earlier we have disused about lexical analyzer in our content compiler in computer. We have learned that the compiler performs the analysis of the source program through different phases to transform it to the target program. The lexical analysis is the first phase that the source program has to go through.
The lexical analysis is the process of tokenizing i.e. it reads the input string of a source program character by character and as soon as it identifies an end of the lexeme, it identifies its pattern and converts it into a token.
The lexical analyzer consists of two consecutive processes that include scanning and lexical analysis.
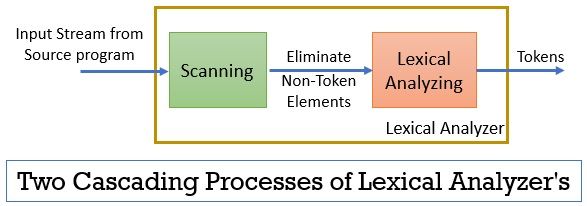
- Scanning: The scanning phase-only eliminates the non-token elements from the source program. Such as eliminating comments, compacting the consecutive white spaces etc.
- Lexical Analysis: Lexical analysis phase performs the tokenization on the output provided by the scanner and thereby produces tokens.
The program used for performing lexical analysis is referred to as lexer or lexical analyzer. Now let us take an example of lexical analysis performed on a statement:
Example 1 of Lexical Analysis:
Lexical analysis in compiler design, identify tokens.
Now, when we will read this statement then we can easily identify that there are nine tokens in the above statement.
- Identifiers -> lexical
- Identifiers -> analysis
- Identifiers -> in
- Identifiers -> compiler
- Identifiers -> design
- Separator -> ,
- Identifiers -> identify
- Identifiers -> tokens
- Separator -> .
So as in total, there are 9 tokens in the above stream of characters.
Example 2 of Lexical Analysis:
Now let us try to find tokens out of this input stream.
- Keyword -> printf
- Special Character -> (
- Literal -> “Value of i is %d ”
- Separator -> ,
- Identifier -> i
- Special Character -> )
- Separator -> ;
- The entire string inside the double inverted commas i.e. “ ” is considered a single token.
- The blank white space separating the characters in the input stream only separates the tokens and thus it is eliminated while counting the tokens.
Role of Lexical Analyzer
Being the first phase in the analysis of the source program the lexical analyzer plays an important role in the transformation of the source program to the target program.
This entire scenario can be realized with the help of the figure given below:
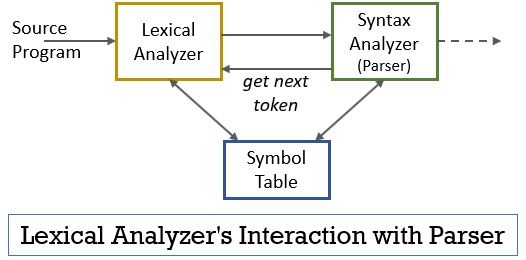
- The lexical analyzer phase has the scanner or lexer program implemented in it which produces tokens only when they are commanded by the parser to do so.
- The parser generates the getNextToken command and sends it to the lexical analyzer as a response to this the lexical analyzer starts reading the input stream character by character until it identifies a lexeme that can be recognized as a token.
- As soon as a token is produced the lexical analyzer sends it to the syntax analyzer for parsing.
- Along with the syntax analyzer, the lexical analyzer also communicates with the symbol table. When a lexical analyzer identifies a lexeme as an identifier it enters that lexeme into the symbol table.
- Sometimes the information of identifier in symbol table helps lexical analyzer in determining the token that has to be sent to the parser.
- Apart from identifying the tokens in the input stream, the lexical analyzer also eliminates the blank space/white space and the comments of the program. Such other things include characters the separates tokens, tabs, blank spaces, new lines.
- The lexical analyzer helps in relating the error messages produced by the compiler. Just, for example, the lexical analyzer keeps the record of each new line character it comes across while scanning the source program so it easily relates the error message with the line number of the source program.
- If the source program uses macros, the lexical analyzer expands the macros in the source program.
Lexical Error
The lexical analyzer itself is not efficient to determine the error from the source program. For example, consider a statement:
prtf(“ value of i is %d ”, i);
Now, in the above statement when the string prtf is encountered the lexical analyzer is unable to guess whether the prtf is an incorrect spelling of the keyword ‘printf’ or it is an undeclared function identifier.
But according to the predefined rule prtf is a valid lexeme whose pattern concludes it to be an identifier token. Now, the lexical analyzer will send prtf token to the next phase i.e. parser that will be handling the error that occurred due to the transposition of letters.
Error Recovery
Well, sometimes it is even impossible for a lexical analyzer to identify a lexeme as a token, as the pattern of the lexeme does not match any of the predefined patterns for tokens. In this case, we have to apply some error recovery strategies.
- In panic mode recovery the successive character from the lexeme is deleted until the lexical analyzer identifies a valid token.
- Eliminate the first character from the remaining input.
- Identify the possible missing character and insert it into the remaining input appropriately.
- Replace a character in the remaining input to get a valid token.
- Exchange the position of two adjacent characters in the remaining input.
While performing the above error recovery actions check whether the prefix of the remaining input matches any pattern of tokens. Generally, a lexical error occurs due to a single character. So, you can correct the lexical error with a single transformation. And as far as possible a smaller number of transformations must convert the source program into a sequence of valid tokens that it can hand over to the parser.
Key Takeaways
- Lexical analysis is the first phase in the analysis of the source program in the compiler.
- The lexical analyzer is implemented by two consecutive processes scanner and lexical analysis.
- Scanner eliminates the non-token elements from the input stream.
- Lexical analysis performs tokenization.
- Thus, the lexical analyzer generates a sequence of tokens and forward them into the parser.
- The parser on possessing a token from the lexical analyzer makes a call getNextToken that insist the lexical analyzer read the input stream of characters until it identifies the next token.
- If the lexical analyzer identifies the pattern of a lexeme as an identifier then the lexical analyzer enters that lexeme into the symbol table for future use.
- Lexical analyzer is not efficient to identify any error in the source program alone.
- If there occurs a lexeme whose pattern does not match any of the predefined patterns of tokens then you have to perform error recovery actions to fix the error.
So, this is all about the lexical analysis which transforms the stream of characters into tokens and passes it to the parser. We have learned about the working of lexical analysis with the help of an example. We have concluded the discussion with the lexical error and its recovery strategy.
Leave a Reply