Distance Vector Routing protocol is a ‘dynamic routing’ protocol. With this protocol, every router in the network creates a routing table which helps them in determining the shortest path through the network. All the routers in the network are aware of every other router in the network and they keep on updating their routing table periodically. This protocol uses the principle of Bellman-Ford’s algorithm.
In this section, we will discuss the distance vector routing protocol in brief along with the Bellman-Ford’s algorithm and distance vector routing algorithm with an example. We will also discuss the advantages and disadvantages of distance vector routing protocol.
Content: Distance Vector Routing Protocol
- What is Distance Vector Routing Protocol?
- Bellman-Ford Algorithm
- Distance Vector Routing Algorithm
- Distance Vector Routing Protocol Example
- Advantages and Disadvantages
- Key Takeaways
What is Distance Vector Routing Protocol?
Distance vector routing protocol is an intradomain routing protocol. Intra domain routing means routing inside the autonomous system (i.e. cluster of routers and networks authorized by a single administrator). The distance vector routing protocol considers the entire autonomous system as a graph, where routers are the nodes and the networks are the lines or paths connecting the nodes.
Each path has some cost or distance associated with it which a datagram has to pay off to travel from one node to another. The paths with smaller cost are more appealing and are preferred over the path with a larger cost to reach the destination. Each router in the system organizes this information in a distance-vector table or routing table.
Every router advertises this distance vector routing table to its neighbouring routers only, after the regular intervals. Routers receiving this advertise use distance vector to update their routing table and calculate the shortest path through the network. After updation, the routers send there updated distance-vector table to their neighbour routers and thus the routing table of every router is updated periodically.
Bellman-Ford’s Algorithm
The distance vector routing protocol uses the basic principle of the Bellman-Ford Algorithm to identify the shortest path through the network. So, let us take a quick review of Bellman-Ford’s algorithm.
As we have learned above, each path connecting the nodes is associated with the cost. So, to calculate the shortest distance follow the following steps:
- Initially, the cost or a distance of a node to itself is set to 0.
- The cost of a node to any other node is set to infinity ‘∞’ if the nodes are not connected directly.
The minimal distance between the two nodes in a graph is calculated using the method below:
Dij = min {(Ci1 + D1j), (Ci2 + D2j), … (CiN + DNj)}|
Dij shortest distance between node i and j
Ci1cost between node i and node 1
This algorithm is repeated until we find the shortest distance vector between two nodes.
Distance Vector Routing Algorithm
Bellman-Ford’s algorithm was designed with the view that we have all the initial information about each node in the graph at the same place. So, the Bellman-Ford algorithm was able to generate a result for each node synchronously.
In distance vector routing algorithm, we have to create the routing table for the routers in the autonomous system. In the autonomous system there can be changes like a new router has been added to the system or some network has stopped the services to a router or a link has failed.
In such situations, the routing table of every router must be updated asynchronously. Because a router has to update its routing table on the basis of information it receives from its neighbouring routers. So, the Bellman-Ford algorithm needs to be modified to design the distance vector routing algorithm:
- In distance vector routing algorithm, the cost is considered as the hop count (number of networks passed to reach the destination node). So a cost between two neighbouring routers is set to 1.
- Each router updates its routing table when it receives the information (distance vector) form the neighbouring routers.
- After updating its routing table, a router must forward its result to its neighbouring router. So that they can update their routing table.
- Each router keeps the three information in its routing table i.e. destination network, cost & the next hop.
- The router sends the information of each route as a record R.
Example of Distance Vector Routing
Let us understand this algorithm with an example:
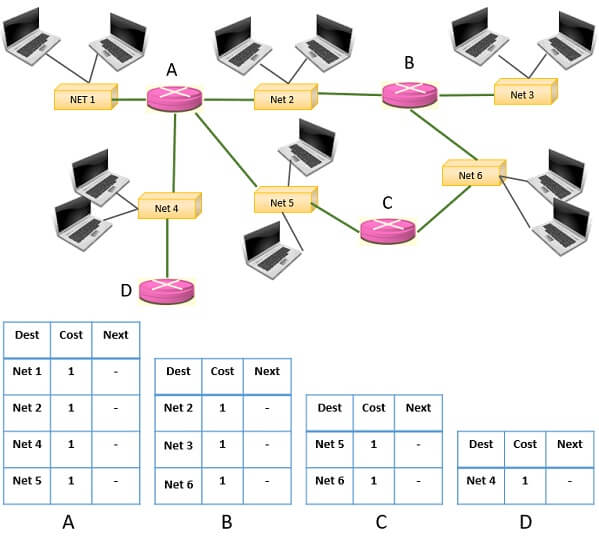
Initially, we can see that all the routers have their own routing table. But, these routing tables are not created synchronously. Whenever a router is booted it creates its routing table.
Now, let us consider that router A has shared records of its routing table with all its neighbour i.e. B, C & D. For understanding we take the scenario where A is sharing records of its routing table with router B.
In the diagram below we have discussed the changes in the routing table of router B as it receives records from router A.
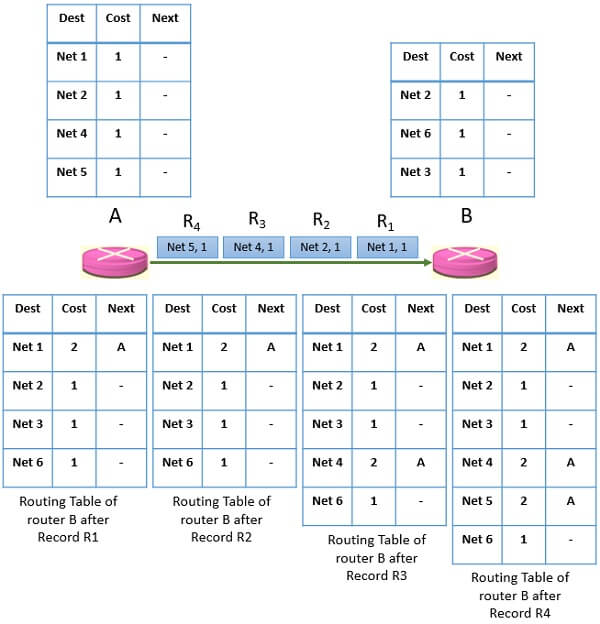
When router B receives the first record ‘Net 1, 1’ it checks its routing table for the route to Net1 and as it is not there in its routing table it adds Net 1 to it routing table with the next hop to be A and it also adds 1 hop to the existing cost of the record.
When router B receives the second record from A ‘Net 2, 1’, it checks its routing table and finds that it already exists in the routing table. Now, the record cost plus 1 seems to be larger than the cost in the routing table so it discards the entire record.
When router B receives the record R3 ‘Net 4, 1’. It checks its routing table and finds that the route to Net 4 is not there. So, it adds Net 4 to its routing table and adds 1 hop to the existing cost in the record with next-hop A.
The same thing happens with record R4. Net 5 is not in the routing table of router B. So, it adds the same to its routing table and adds 1 hop to the cost of record along with the next-hop A.
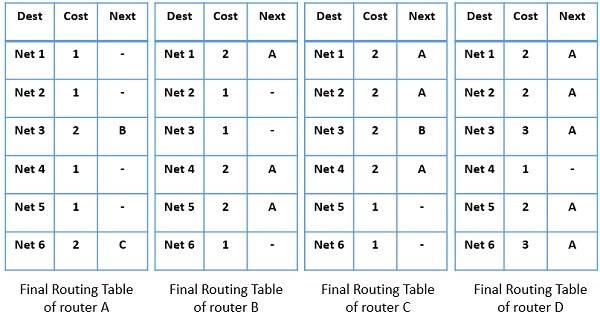
In a similar way, router A, C and D also update their routing table and send the updated information to their neighbouring router. The final routing tables of all the routers for the current scenario would be like:
Advantages & Disadvantages of Distance Vector Routing
Advantages
- Distance vector routing protocol is easy to implement in small networks. Debugging is very easy in the distance vector routing protocol.
- This protocol has a very limited redundancy in a small network.
Disadvantage
- A broken link between the routers should be updated to every other router in the network immediately. The distance vector routing takes a considerable time for the updation. This problem is also known as count-to-infinity.
- The time required by every router in a network to produce an accurate routing table is called convergence time. In the large and complex network, this time is excessive.
- Every change in the routing table is propagated to other neighbouring routers periodically which create traffic on the network.
Key Takeaways
- Distance vector routing protocol is a dynamic routing protocol.
- It is based on the principle of Bellman-Fords algorithm.
- This protocol helps the router to find the shortest path through the network.
- Each router is aware of every other router in the network.
- Each router shares the updated records of the routing table with the neighbouring routers which help them to update their routing table. The neighbouring routers, in turn, send their updated information to their neighbouring routers.
So that’s all about the distance vector routing protocol. The Routing Information Protocol (RIP) implements the distance vector routing protocol to find the best path in the network along with some considerations.
gilberz says
I don’t even understand how I finished up here, but I thought this put up was good. I don’t recognize who you are but certainly
you are going to a well-known blogger Cheers!