Parallelism in a uniprocessor means a system with a single processor performing two or more than two tasks simultaneously. Parallelism can be achieved by two means hardware and software. Parallelism increases efficiency and reduces the time of processing.
In this section, we will discuss the structure of a uniprocessor system, and how parallelism can be promoted in the uniprocessor system.
What is Uniprocessor?
A uniprocessor is a system with a single processor which has three major components that are main memory i.e. the central storage unit, the central processing unit i.e. CPU, and an input-output unit like monitor, keyboard, mouse, etc.
To understand the structure of a uniprocessor system we will study the architectural two structures of systems. First is a super minicomputer VAX-11/780 which was manufactured by Digital Equipment Company and the second is the mainframe computer 370/Model 168 by IBM.
VAX-11/780
Observe the figure below to analyze the structure of the VAX system. We will first analyze the central processing unit of the VAX system which has sixteen 32-bit general-purpose registers from R0 to R15. Among these 16 registers, one of the registers serves as the program counter which holds the address of the next instruction to be executed. And one other register serves the purpose of the status register which holds the status of the current program in execution.
The CPU of the VAX system also has a local cache memory with an optional diagnostic memory which is used while diagnosing any errors. It has an arithmetic logic unit along with a floating-point accelerator that performs the floating-point arithmetic operation. The operator can intercede the CPU operations through the console which is also connected to the floppy disk.
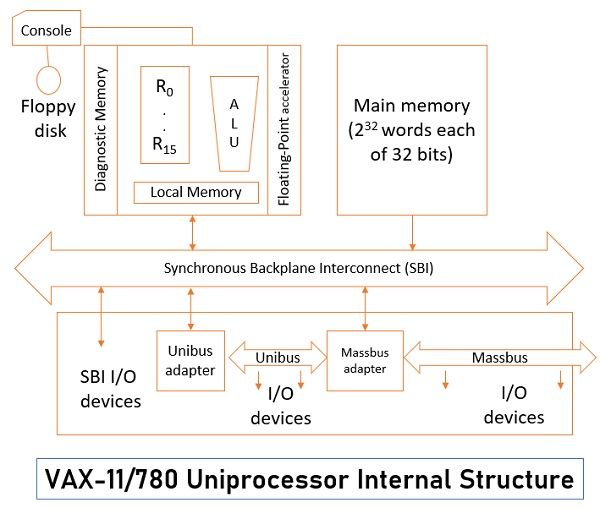
Now the main memory, CPU, and other I/O devices are interconnected with the help of a common bus which is synchronous backplane interconnect (SBI).
Mainframe IBM System 370
The CPU of this system has an instruction decoding and executing unit along with the cache memory. The main memory here is divided into four units logical state units. The main memory has a storage controller which connects the four logical state units with the CPU.
The I/O devices are connected to the CPU via high-speed I/O channels.
Parallelism in Uniprocessor
The parallelism in uniprocessors can be introduced either using hardware or software. We will first begin with hardware approaches and later study the software approach to achieve parallelism in the uniprocessor along with better utilization of the system resources.
Hardware Approach for Parallelism in Uniprocessor
1. Multiplicity of Functional Unit
In earlier computers, the CPU consists of only one arithmetic logic unit which used to perform only one function at a time. This slows down the execution of the long sequence of arithmetic instructions. To overcome this the functional units of the CPU can be increased to perform parallel and simultaneous arithmetic operations.
2. Parallelism and Pipelining within CPU
Parallel adders can be implemented using techniques such as carry-lookahead and carry-save. A parallel adder is a digital circuit that adds two binary numbers, where the length of one bit is larger as compared to the length of another bit and the adder operates on equivalent pairs of bits parallelly.
The multiplier can be recoded to eliminate more complex calculations. Various instruction execution phases are pipelined and to overcome the situation of overlapped instruction execution the techniques like instruction prefetch and data buffers are used.
3. Overlapped CPU and I/O Operation
To execute I/O operation parallel to the CPU operation we can use I/O controllers or I/O processors. For direct information transfer between the I/O device and the main memory, direct memory access (DMA) can be used.
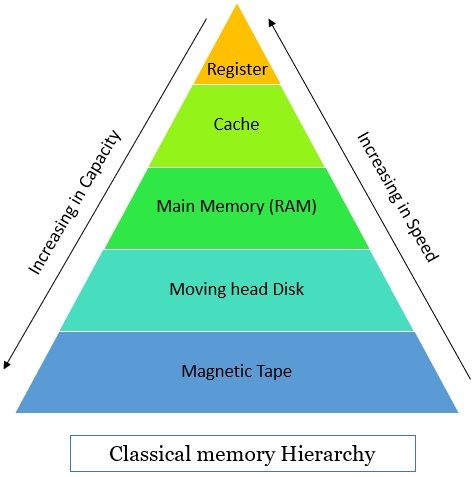
4. Use Hierarchical Memory System
We all are aware of the fact that the processing speed of the CPU is 1000 times faster than the memory accessing speed which results in slowing the processing speed. To overcome this speed gap hierarchical memory system can be used. The faster accessible memory structure is registered in CPU, then cache memory which buffers the data between CPU and main memory.
Then comes the main memory which has the program which is being executed currently. The figure below explains the hierarchy of the memory system.
5. Balancing of Subsystem Bandwidth
The processing and accessing time of CPU, main memory, and I/O devices are different. If arrange the processing time of these units in descending order the order would be:
td> tm>tp
where td is the processing time of the device, tm is the processing time of the main memory, and tp is the processing time of the central processing unit. The processing time of the I/O devices is greater as compared to the main memory and processing unit. CPU is the fastest unit.
To put a balance between the speed of CPU and memory a fast cache memory can be used which buffers the information between memory and CPU. To balance the bandwidth between memory and I/O devices, input-output channels with different speeds can be used between main memory and I/O devices.
Software Approach for Parallelism in Uniprocessor
1. Multiprogramming
There may be multiple processes active in computers and some of them may be competing for memory some for I/O devices and some for CPU. So, to establish a balance between these processes, program interleaving must be practiced. This will boost resource utilization by overlapping the I/O and CPU operations.
Program interleaving can be understood as when a process P1 is engaged in I/O operation the process schedular can switch CPU to operate process P2. This led process P1 and P2 to execute simultaneously. This interleaving between CPU and I/O devices is called multiprogramming.
2. Time-Sharing
Multiprogramming is based on the concept of time-sharing. The CPU time is shared among multiple programs. Sometimes a high-priority program can engage the CPU for a long period starving the other processes in the computer.
The concept of timesharing assigns a fixed or variable time slice of CPUs to multiple processes in the computer. This provides an equal opportunity to all the processes in the computer.
So, in this way, we can effectively introduce parallelism in the uniprocessor. Parallelism increases the efficiency of the system and makes computation even faster. We have seen both the approaches hardware and software to introduce parallelism in a system with a single processor.
Leave a Reply