Parallel processing requires multiple processors and all the processor works simultaneously in the system. Here, the task is divided into subparts and these subparts are then distributed among the available processors in the system. Parallel processing completes the job on the shortest possible time.
Let us understand the scenario with the help of a real-life example:
Consider the single-processor system as the one-man company. In a one-man company the owner takes a task finishes it and further takes another task to accomplish.
If the owner has to expand his business, he has to hire more people. Hiring more people will distribute the workload and allow him to finish the jobs faster. He will also be able to increase his capacity for doing jobs. Or we can say he will able to accept more jobs than earlier. This strategy is similar to parallel processing.
Growing more if this entrepreneur opens up his branch offices and distributes different functions to different branches in order to work more efficiently. Then this strategy will be similar to distributed computing. Here, we will discuss parallel processing in brief.
Content: Parallel Processing in Operating System
- Introduction
- Hardware Supporting Parallel Processing
- Operating Systems for Parallel Processing
- Advantages
- Key Takeaways
Introduction
As we discussed above parallel processing breaks the task or a process into sub-tasks and distribute these sub-tasks among all the available processors present in the system. Thereby, executing the task in the shortest time.
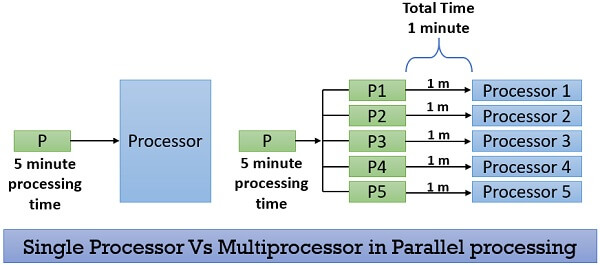
All the processors in the parallel processing environment should run on the same operating system. All processors here are tightly coupled and are packed in one casing. All the processors in the system share the common secondary storage like the hard disk. As this is the first place where the programs are to be placed.
There is one more thing that all the processors in the system share i.e. the user terminal (from where the user interact with the system). The user need not to be aware of the inner architecture of the machine. He should feel that he is dealing with the single processor only and his interaction with the system would be the same as in a single processor.
If the user is aware of the count of the processors present in the system, he would always try to divide his job on the basis of the number of processors present in the system.
Suppose there are ten processors in the system and if the user is aware of this. Then he will always try to divide his job into ten subparts. But doing this will create a problem for the created application. If the application is ported on another system where there are only 8 processors. Ultimately here the job will either fail or it needs to be rewritten.
Hardware Supporting Parallel Processing
1. Bus-based Intercommunication
Parallel processing includes multiple processors and these processors use a single bus to access the shared memory. Here, all the processors present in the system have a local memory (cache). Initially, the processor looks for the required data in their local memory. In case, the data is not found in the cache memory, then the processor accesses the bus for reading the shared memory.
In the following figure, you can see the bus-based architecture where the processors P1, P2, P3, share the memory using a single bus.
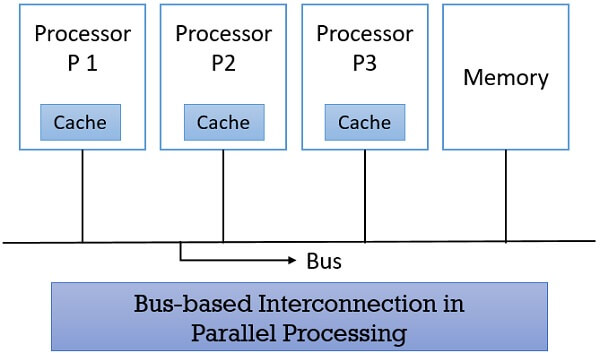
Think, if the processor wouldn’t have the cache memory, then the system would have been bounded to the bandwidth of the bus. As there will always be one of the processor present accessing the bus to read the shared memory. So other processors would have to wait until the bus is free and have to sit idle most of the time waiting for the availability of the bus.
Having its own cache memory, if the processors are programmed to do specific functions then the amount of bus access to read shared memory would reduce. This is because the code for the specific function would be there in their cache memory. The bus access will only be required to read the common shared data.
2. Switched Memory Access
The interconnection between the processors is made here by using the crossbar switch. This technique is similar to the old technique of telephone exchange where they used the crossbar switch to connect the group of an incoming line to the outgoing lines.
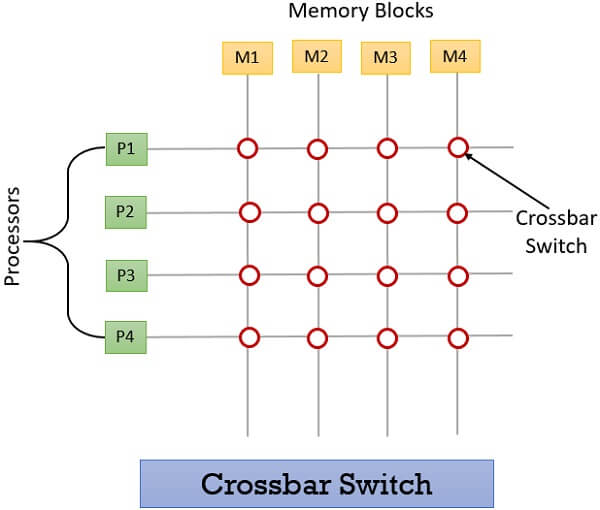
Following this strategy, the shared memory is split into the number of memory blocks. Each processor in the system has access to all the divided memory blocks. But there is one limitation, two processors can never access the same memory block at the specific time.
To understand the scenario, of using the crossbar switch in parallel processing. Consider that we have 4 processors P1, P2, P3, P4 and we have divided the shared memory into 4 parts M1, M2, M3, M4.
When the processor P1 is accessing the memory block M1, it can continue to access it till it requires. But during that duration, no other processor have right to access memory block M1. In case any of the other processors try to access the memory block M1 then they will find a busy signal. They have to wait till the processor P1 has finished accessing M1.
There is a solution to this problem, we can arrange a memory block and processor in such a way that the particular processor has to access a specific memory block most of the time. Following this strategy can allow us to have as many processors as needed.
But using crossbar switch implies that there must number of memory blocks as there are processors. So, if there are n processors, n memory block would be needed, and to connect these processors to memory block it will require nxn switches. Thus it appears costly to implement parallel processing using crossbar switch. Even the switches here have low reliability.
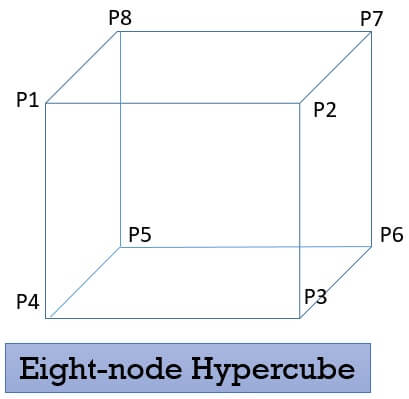
3. Hypercubes
It says if there are n processors in the system. Then each processor would be connected to log n base 2. Here each processor has its own memory and other I/O devices. We can say that each processor here is a complete computer. There has been a lot of research done on this type of systems. Below is the diagram of an eight-node hypercube. Processor P1 here is connected to processor P2, P8 and P4.
Operating Systems for Parallel Processing
1. Separate operating system
Here, each processor has its own copy of the operating system, memory, file system and I/O devices. It is an ideal hypercube architecture where each node is a computer.
This system can be built using readily available products. But each processor has to run its own operating system and this takes lots of execution time and memory.
2. Master/Slave operating system
There is a one master processor which executes the operating system and consider the other slave processors as a resource like memory or I/O devices. The master processor knows the ability of each processor and allots them resources and task accordingly.
If the master processor fails, then the entire system fails.
3. Symmetric Operating System
In the symmetric operating system, each processor is identical in every sense. All the operating system’s data structures are placed in the global memory and are accessible to all the processors.
Each processor has a microkernel and has limited functionality of performing the basic processing. It is an efficient parallel system. As if one or two processor fails then it will low down the system but won’t let it become standstill.
It is complex, difficult to build and debug.
Advantages
- Increasing the number of processors will increase the throughput of the system.
- In parallel processing if one of the processors in the system fails, the process is further rescheduled to get executed on another processor, it increases fault tolerance.
- The system can be configured according to the need. With the increasing need for computing, the number of processors can also be increased.
- The maintenance, build-up cost is lower as components are commercially available.
Key Takeaways
- Parallel processing divides the job into sub-parts and distributes them among the available processers thereby executing the job in the shortest time.
- All the processors have a common operating system.
- All the processors are tightly coupled.
- All processors share the common secondary storage.
- All the processors share the user terminal.
So this was all about parallel processing and this strategy helps in executing the processes faster than in a single processor system.
Daniel says
This is very interesting, You’re a very skilled blogger.
I have joined your feed and look forward to seeking more of your magnificent post. Also, I have shared your web site in my social networks!
Bhanu Prakash D N says
Thanks for the good content with an good example .. : )