Aggregate functions in SQL evaluate the set of values and return a single value as a result. SQL has five aggregate functions count, average, maximum, minimum, sum. The aggregate functions, ‘sum’ and ‘average’ operate only on numeric values. While count, maximum, minimum can also operate on non-numeric data such as string.
In this section, we will discuss the steps to evaluate aggregate functions. We will discuss types of aggregate functions. We will also look into the use of aggregate function along with the ‘group by’ clause and ‘having’ clause.
Content: Aggregate Function in DBMS
- How to Aggregate Data?
- Aggregate Functions
- Aggregation with Group by Clause
- Aggregation with Having Clause
- Key Takeaways
How to aggregate data in SQL?
Step by step evaluation of the aggregate function in SQL.
- The first thing evaluated in the query is the ‘from’ clause. The ‘from’ clause evaluates the relation to be operated.
- Next to the ‘from ‘clause is the ‘where’ clause. The predicate in the ‘where’ clause is evaluated on the outcome of the ‘from’ clause.
- If present, the tuples filtered by the ‘where’ clause are then grouped using the ‘group by‘ clause. Else all the tuples filtered by the ‘where’ clause are considered as one group.
- The ‘having’ clause is then applied to each group formed by the ‘group by‘ clause. And the groups satisfying the ‘having’ clause are then forwarded to the ‘select’ clause.
- Then the ‘select’ clause applies the aggregate function to the evaluated groups. And generates a single result tuple for each group.
Define Aggregate Functions in DBMS
The aggregate functions are applied to the set of tuples. And as a result, they return a relation with a single attribute consisting of a single tuple value. It can also be applied to the group of ‘sets of tuples’. It results in a relation with a single attribute and one tuple for each group.
All aggregate functions avoid ‘null values’ excluding the (*) function. Count function has variations regarding Null values.
Below is the list of all aggregate functions in SQL:
Note: We can name the attribute of the result relation obtained by aggregation using the ‘as’ clause. We can use the ‘as’ clause for all aggregate functions.
How to Use the Aggregate function in SQL?
COUNT( ) Aggregate Function
This aggregate function counts the number of tuples in the relation. It has certain variations:
- count(*)
This function returns the number of tuples, including those with ‘Null values’. - count(attribute_name)
This function counts all the tuples with ‘not-null values’. - count(distinct attribute_name)
This function eliminates tuples with ‘null values’ and ‘duplicate values’. It only counts the tuples with not-null values and distinct values.
Example of COUNT( ) Aggregate Function:
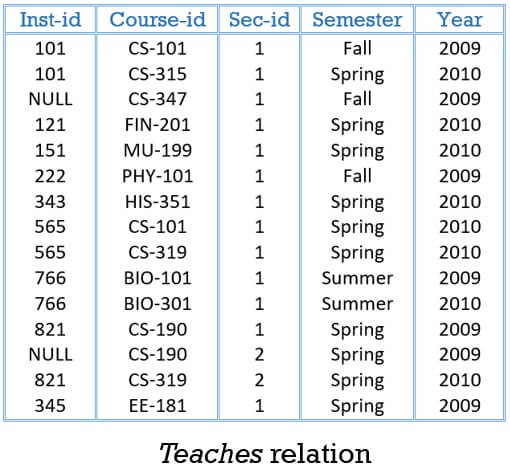
If you want to count the number of instructors in the teaches relation then the query for this would be:
select count(inst-id)
from teaches;
The query above will return 13 as a result. Here the count function avoids Null values.
Next, if we add the distinct keyword in the count function.
select count (distinct inst-id)
from teaches;
This query returns 9 as a ‘distinct’ keyword is used along with the attribute name in the count function. So, it has eliminated the duplicates along with null values.
Now, in the next query if we apply * in count():
select count(*)
from teaches;
This query will return 15 as it has counted all the tuples including the Null values.
Average ‘AVG()’ Aggregate Function
The AVG() function returns the average of all the tuple values from a single attribute of a relation. Remember the duplicate tuples must retain while computing an average. Else it will show an incorrect answer. This function avoids the ‘Null value’ in its input as it complicates the aggregation.
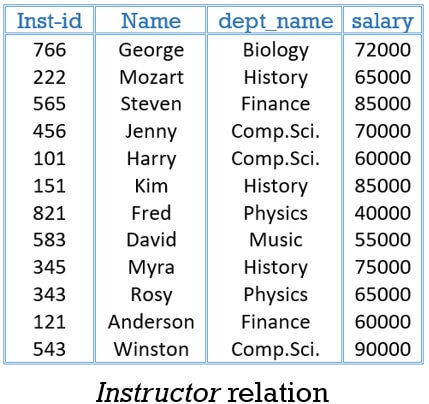 Example of AVG( ) Aggregate Function:
Example of AVG( ) Aggregate Function:
Evaluate “average salary of all the instructors teaching in Comp.Sci. department”.
Select avg(salary)
from instructor
where dept_name=‘Comp.Sci.’;
The result of this query will be a relation with a single attribute carrying a single record. This record holds a numerical value. The numerical value shows the average salary of all instructors teaching in Comp. Sci. department (result 73,333.333).
You can also provide a meaningful name to the attribute of result relation, using the ‘as’ clause. Else, the database system will give an arbitrary name to the attribute of the result relation. The query below shows how can we provide a name to the attribute of result relation?
select avg(salary) as avg_salary
from instructor
where dept_name =‘Comp.Sci.’

Maximum ‘MAX()’ Aggregate Function
This function evaluates the maximum value among all the tuple values, of the specified attribute. Like other aggregate functions, the max() avoid the’ null values’ in its input.
Example of MAX( ) Aggregate Function:
The query below will result in the maximum salary of all the instructors.
select max(salary) as max_salary
from instructor;

Minimum ‘MIN()’ Aggregate Function
Contrary to max() is the min() aggregate function. It evaluates the minimum value among all the tuple values, of the specified attribute. The min() aggregate function avoid ‘null values’ in its input.
Example of MIN( ) Aggregate Function:
To find the minimum salary of all instructors in the instructor relation we will write the query:
select min(salary) as min_salary
from instructor;

Total ‘SUM()’ Aggregate Function
This function evaluates the sum of all the tuple values, of the specified attribute. Like average function, sum also drives on numerical values only. The sum function avoids the null values.
Example of SUM( ) Aggregate Function:
The query below will find the total salary of all the instructors.
select sum(salary) as sum_salary
from instructor;

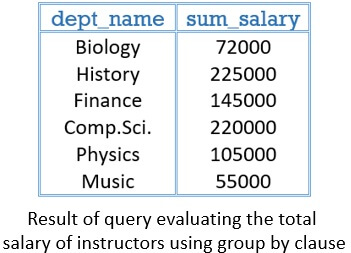
‘Group by’ with Aggregate Function
We can apply aggregate functions to a group formed by the ‘group by clause’. The tuples with the same value for the specified attributes in the ‘group by’ clause lies in one group.
Example of ‘Group by’ Aggregate Function:
So, if we have to calculate the total salary of instructors in each department then the query would be:
select dept_name sum(salary) as sum_salary
from instructor
group by dept_name;
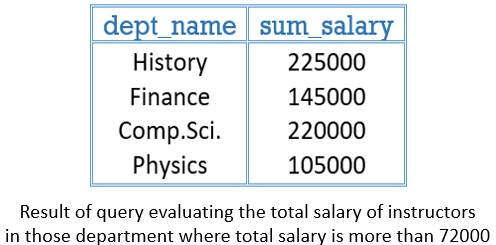
‘Having’ with Aggregate Function
Having clause is the condition applied to each of the groups formed by the ‘group by’ clause. If the formed groups do not satisfy the condition then they are removed from the result.
Example of ‘Having’ Aggregate Function:
If we want the department names whose total salary of instructors is greater the 72000. Then the query would be:
select dept_name sum(salary) as sum_salary
from instructor
group by dept_name
having sum(salary)>72000;
Key Takeaways:
- Aggregate functions are applied to the set of tuple values. And they return a relation with a single attribute consisting of a single tuple.
- We have five aggregate functions count, average, maximum, minimum and sum.
- The average and sum functions operate only on numerical values. The other aggregate function can also operate on non-numerical values.
- All aggregate functions avoid null values while operating except count(*).
- Aggregate functions can also be used along with, the ‘group by‘ clause and ‘having‘ clause.
So this was all about the aggregate functions in SQL. Always apply the sum and average function to the attribute with numerical values.
Leave a Reply