A data cube in a data warehouse is a multidimensional structure used to store data. The data cube was initially planned for the OLAP tools that could easily access the multidimensional data. But the data cube can also be used for data mining.
Data cube represents the data in terms of dimensions and facts. A data cube is used to represents the aggregated data. A data cube is basically categorized into two main kinds that are multidimensional data cube and relational data cube.
In this section, we will discuss the term data cube along with its classification. Further, we will discuss the operations that could be conducted on the data cube. We will also discuss the benefits of using the data cube for storing data in the data warehouse.
Content: Data Cube in Data Warehouse
- What is Data Cube?
- Data Cube Classification
- Operations on Data Cube
- Advantages of Data Cube
- Key Takeaways
What is Data Cube?
A data cube is a multidimensional data model that store the optimized, summarized or aggregated data which eases the OLAP tools for the quick and easy analysis. Data cube stores the precomputed data and eases online analytical processing.
When it comes to cube, we, all think it as a three-dimensional structure but in data warehousing, we can implement an n-dimensional data cube.
Data stored in a data cube is represented in terms of dimensions and facts. Now, what does the dimension exactly represents?
The dimensions of data cube are the attitude, angle or the entities with respect to which the enterprise wants to store the data. Now, how does it help the analyst to analyze and extract the data?
Let us take an example, consider we have data about AllElectronics sales. Here we can store the sales data in many perspectives or dimensions like sales in all time, sale at all branches, sales at all location, sales of all items. The figure below shows the data cube for AllElectronics sales.
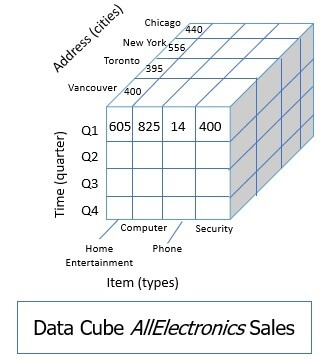
Each dimension has a dimension table which contains a further description of that dimension. Such as a branch dimension may have branch_name, branch_code, branch_address etc.
A multidimensional data model like data cube is always based on a theme which is termed as fact. Like in the above example of a data set of AllElectronic we have stored data based on the sales of the electronic item. So, here the fact is sales. A fact has a fact table associated with it.
The fact table has the data in numeric forms which denotes the numeric measures such as a number of units of an item sold, sale of a particular branch in a particular year, etc. Knowing data cube let us further move to the data cube classification.
Data Cube Classification
Data cube can be classified into two main categories as discussed below:
1. Multidimensional Data Cube (MOLAP)
Multidimensional arrays are used to store data that assures a multidimensional view of the data. Multidimensional data cube helps in storing a large amount of data.
Multidimensional data cube implements indexing to represent each dimension of a data cube which improves the accessing, retrieving and storing data from the data cube.
2. Relational Data cube (ROLAP)
You can consider the relational data cube as the ‘extended version of relational DBMS’. Relational tables are used to store data and each relational table represents the dimension of a data cube.
To calculate the aggregated data relational data cube implements SQL but when it comes to performance the relational data cube’s performance is slower than the multidimensional data cube. But the relational data cube is scalable for steadily increasing data.
You can even get the combination of both relational data cube as well as multidimensional data cube which is termed as a hybrid data cube. The hybrid data cube (HOLAP) retrieve features such as scalability from relational data cube and it retrieves faster computation from multidimensional data cube.
Operations on Data Cube
Now, let us discuss the operations that can be conducted on data cube in order to view data from different angles. There are four basic operations that can be implemented on a data cube which are discussed below:
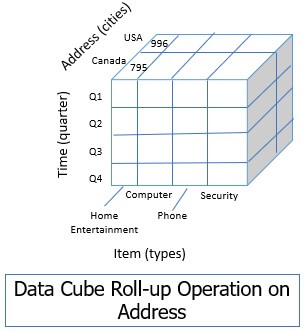
1. Roll Up
Roll-up operation summarizes or aggregates the dimensions either by performing dimension reduction or you can perform concept hierarchy.
The below figure shows you the example of a roll-up operation performed on the location dimension of the data cube we have seen above.
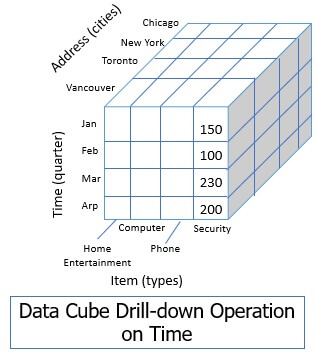
2. Drill Down
When the drill-down operation is performed on any dimension the data on the dimension is fragmented into granular form.
In the figure below you can see the drill-down operation on the time dimension where the quarter Q1, Q2, is fragmented into months.
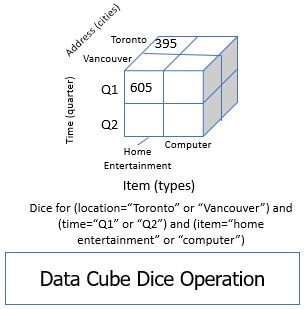
3. Slice and Dice
The slice and dice operation pick up one dimension of the data cube and then forms a subcube out of it. The figure below represents the slice operation on a data cube where the data cube is sliced based on time.
 The dice operation select more than one dimension to form a subcube. Like in the figure below you can see that the subcube is formed by selecting the dimensions such as location, items and time.
The dice operation select more than one dimension to form a subcube. Like in the figure below you can see that the subcube is formed by selecting the dimensions such as location, items and time.
4. Pivot
Pivot is not a calculative operation actually it rotates the data cube in order to view data cube from different dimensions.
The figure below shows the pivot operation performed on the data cube.

So, these are the four operations that can be performed on the data cube.
Advantages of Data Cube
- Data cube ease in aggregating and summarizing the data.
- Data cube provide better visualization of data.
- Data cube stores huge amount of data in a very simplified way.
- Data cube increases the overall efficiency of the data warehouse.
- The aggregated data in data cube helps in analysing the data fast and thereby reducing the access time.
Key Takeaways
- A data cube is a multidimensional data structure model for storing data in the data warehouse.
- Data cube can be 2D, 3D or n-dimensional in structure.
- Data cube represent data in terms of dimensions and facts.
- Dimension in a data cube represents attributes in the data set.
- Each cell of a data cube has aggregated data.
- Data cube provides fast computation and easy access to data and thereby increases the efficiency of the data cube
- Data cube performs indexing to access dimensions.
- Data cube can be categorized into two main types such as multidimensional data cube and relational data cube.
- Multidimensional data cube has fast computation.
- The relational data cube is scalable and is efficient for growing data.
- Roll-up, drill-down, slice and dice, pivoting are the operations that can be performed on a data cube.
So, this is all about data cube, we have discussed the term data cube in brief. We have also studied its categorization along with operations that can be performed to data cube to access the data.
Rohan Hearth says
Thank you so much